
ELMo模型解析

写在开头:ELMo是一个用于生成动态词向量的预训练语言模型,学习该模型需要了解语言模型、词向量、RNN、LSTM这些知识,本文对这些内容不再过多讲解,如果对以上内容不了解的,建议按顺序学习,这样效果更佳哦~
ELMo是什么
ELMo(Embeddings from Language Models)从名字上可以看出来,ELMo模型是一个用于生成词向量的预训练语言模型,它也是根据输入的文本信息(一个单词序列),利用双向LSTM模型分别预测文本序列前向的下一个词和反向的下一个词,以训练出一个动态的词向量模型,具体是怎么个动态法,后面慢慢道来。
为什么要提出ELMo
作为词向量生成模型,已经有了word2vec,那么为什么又提出了ELMo模型呢?其实就是要看word2vec有什么弊端,而ELMo又是如何解决这些弊端的。word2vec生成的词向量最明显的一个弊端就是,生成的词向量是静态的,即一个单词对应就是一个唯一的词向量,但实际情况中同一个单词在不同的语境里有不同的含义,而且有时候是完全不同的含义,这样都用一个词向量来表示的话就会存在问题了,而ELMo模型是一个动态词向量,在对某一个词使用其词向量的时候,需要输入整个文本,根据整个语境信息动态的生成词向量,这样,同一个词在不同的语境下得到的词向量就是不同的值。此外word2vec训练过程中只是利用了周围词的信息,但没有考虑词序,只是把周围词一块加权输入,而ELMo模型由于使用了双向LSTM,训练过程中利用了整个输入文本,而且同时考虑了正向和反向序列输入信息,得到的特征信息更加丰富。
双向LSTM
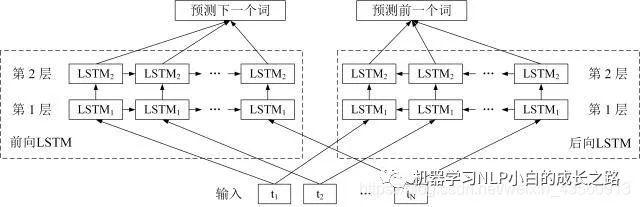
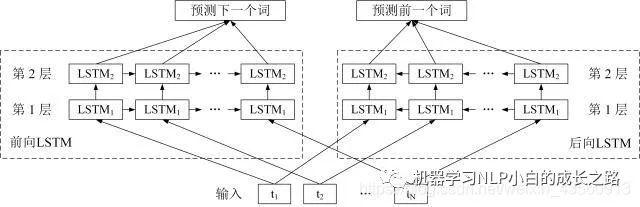
ELMo的核心就是利用了双向的LSTM结构进行特征提取,所以首先介绍一下双向LSTM。双向LSTM(Bi-directional LSTM)简称Bi-LSTM,LSTM模型可以解决序列输入问题,可以利用输入序列的上文信息进行当前词的预测,双向LSTM就是增加将序列反向输入,即正向的输入序列可以得到上文信息,反向输入的序列可以得到下文信息,所以在预测当前词输出时,做到了利用整体上下文的信息进行预测,使得到的结果更加准确。LSTM相关介绍可参照LSTM模型介绍。
比如有一个序列N(t1,t2,..,tn),对于前向语言模型,我们利用前k-1个词来预测第k个词,前向公式为


对于后向语言模型,我们tk之后,tk+1到tn来预测tk,后向公式为:
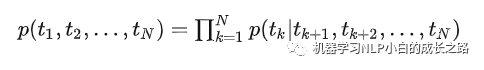
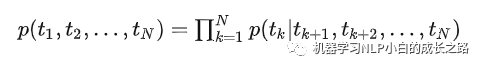
双向的语言模型就是同时利用前向语言模型和后向语言模型,共同来预测tk,训练的目标就是目标词tk的最大似然


ELMo模型结构
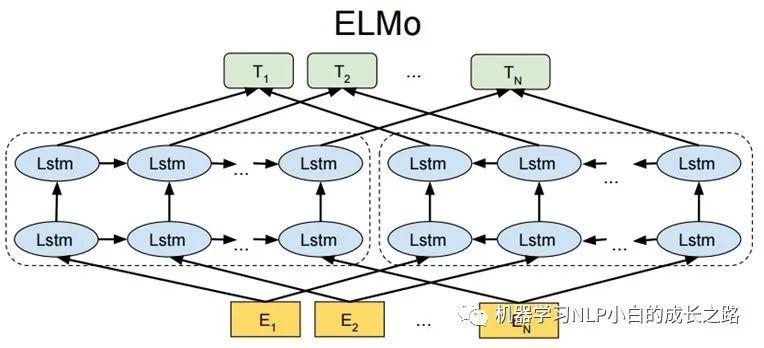

ELMo模型结构图
ELMo算法流程如下:
1.从静态的词向量表里查找单词的词向量 E(1), …, E(N) 用于输入。ELMo 使用 CNN-BIG-LSTM 生成的词向量作为输入。one-hot表征乘以Q矩阵即可完成查询过程。
2.传入到LSTM层
2.1将单词词向量 E(1), …, E(N) 分别输入第 1 层前向 LSTM 和后向 LSTM,得到前向输出 h(1,1,→), …, h(N,1,→),和后向输出 h(1,1,←), …, h(N,1,←)。
2.2将前向输出 h(1,1,→), …, h(N,1,→) 传入到第 2 层前向 LSTM,得到第 2 层前向输出 h(1,2,→), …, h(N,2,→);将后向输出 h(1,1,←), …, h(N,1,←) 传入到第 2 层后向 LSTM,得到第 2 层后向输出 h(1,2,←), …, h(N,2,←)。
3.单词 i 最终可以得到的词向量包括 E(i), h(N,1,→), h(N,1,←), h(N,2,→), h(N,2,←),如果采用 L 层的 biLSTM 则最终可以得到 2L+1 个词向量。
如何获取词向量
一个句子输入到ELMo模型后,其中的一个单词i可以得到2L+1个词向量,那么该如何使用这些词向量作为单词i的词向量表示呢。
首先在 ELMo 中使用 CNN-BIG-LSTM 词向量 E(i) 作为输入,E(i) 的维度等于 512。然后每一层 LSTM 可以得到两个词向量 h(i,layer,→) 和 h(i,layer,←),这两个向量也都是 512 维,拼接后是1024维,则对于单词 i 可以构造出 L+1 个词向量。


h(i,0) 表示两个 E(i) 直接拼接,表示输入词向量,这是静态的,1024 维。
h(i,j) 表示第 j 层 biLSTM 的两个输出词向量 h(i,j,→) 和 h(i,j,←) 直接拼接,这是动态的,1024维。
ELMo 中不同层的词向量往往的侧重点往往是不同的,输入层采用的 CNN-BIG-LSTM 词向量可以比较好编码词性信息,第 1 层 LSTM 可以比较好编码句法信息,第 2 层 LSTM 可以比较好编码单词语义信息。
ELMo作者提供了两种得到词向量的方法:
1.第一种是直接使用最后一层 biLSTM 的输出作为词向量,即 h(i,L)。
2.第二种是更加通用的做法,将 L+1 个输出加权融合在一起,公式如下。γ 是一个与任务相关的系数,允许不同的 NLP 任务缩放 ELMo 的向量,可以增加模型的灵活性。s(task,j) 是使用 softmax 归一化的权重系数。


如何使用ELMo完成下游任务
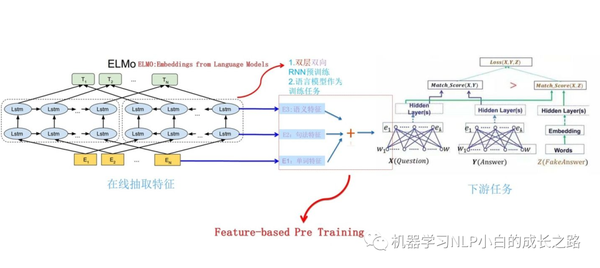
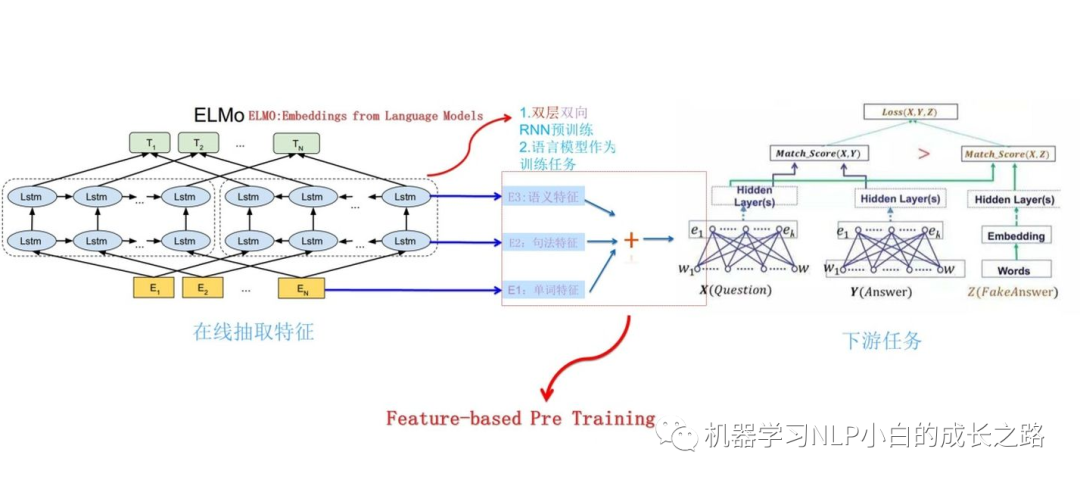
对于下游任务:
1.将句子 X 输入ELMo网络中,这样句子 X 中每个单词在ELMo网络中都能获得对应的三个Embedding;
2.之后赋予每个Embedding一个权重a,这个权重可以由学习得来,根据权重求和之后将三个Embedding整合为一个;
3.将整合后的Embedding作为相应的单词输入,作为新特征给下游任务使用;
从这里可以看出,对于一个单词i的词向量,每次生成时都是根据当前输入的整个序列得到的,因此利用了当前的语境信息,是一个动态得到的词向量,解决了同一个单词在不同语境下含义不同的问题。
注:文章部分内容引用了博客https://blog.csdn.net/weixin_43560913/article/details/118734946