DataWorks实践笔记-从入门到精通

DataWorks是阿里出品的一站式大数据开发与治理平台,基于MaxCompute/EMR/MC-Hologres等大数据计算引擎,网络上的教程很多,但是一般都比较冗长。这里分享我个人在实践过程中摘录的笔记,言简意赅,方便大家快速上手。
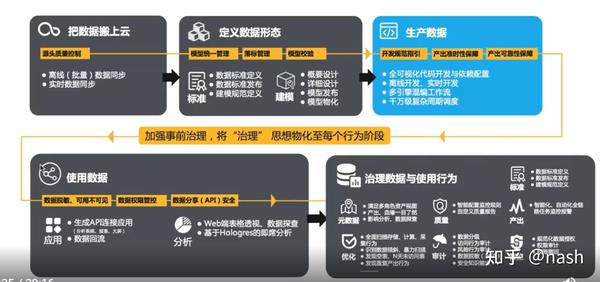
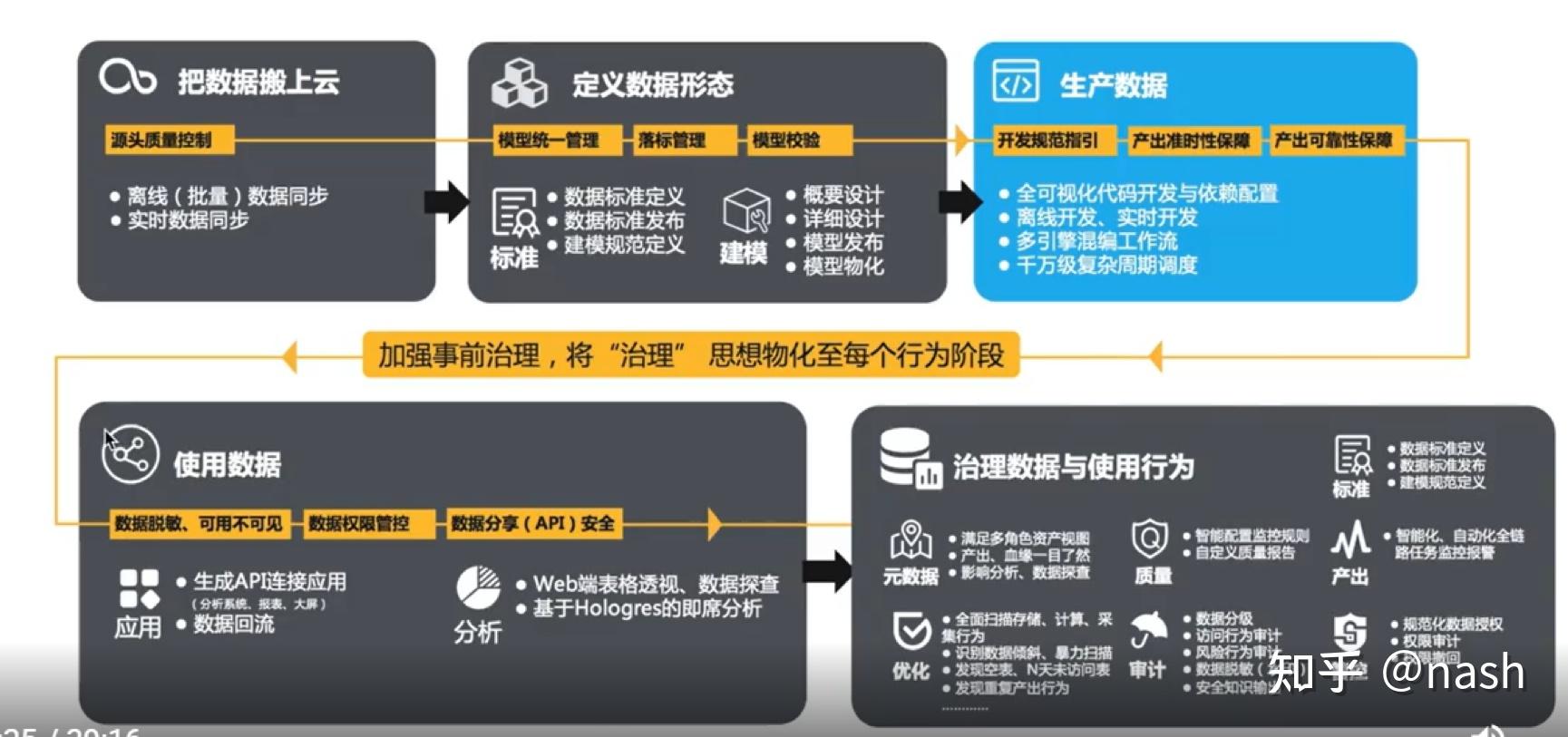
总体介绍
Dataworks有两种数据计算引擎(计算平台),EMR(开源的)和MaxCompute。在这个基础上,有Datahub数据总线引擎,实时计算Flink引擎,交互分析Hologres引擎,图计算Graphcompute引擎,搜索elastic search,open search引擎。除了Dataworks,阿里还提供一个PAI的AI平台。用户通过可视化的方式来调度脚本执行的前后依赖关系,只要会SQL就可以展开大数据开发和分析,同时平台支持数据上线发布和运维工作。
数据仓库架构
阿里将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层(ADS,Application Data Service)。CDM分为:
l 公共维度层(DIM):基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。
l 公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
l 明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。明细粒度事实层的表通常也被称为逻辑事实表。
表管理
在maxcompute里,表有“分区”的概念,分区可以使某些查询以及维护操作的性能大大提高。分区表是指拥有分区空间的表,即在创建表时指定表内的一个或者某几个字段作为分区列。分区表实际就是对应分布式文件系统上的独立的文件夹,一个分区对应一个文件夹,文件夹下是对应分区所有的数据文件。
MaxCompute表的生命周期(Lifecycle),指表(分区)数据从最后一次更新的时间算起,在经过指定的时间后没有变动,则此表(分区)将被MaxCompute自动回收。这个指定的时间就是生命周期。
在dataworks一般会以数据同步的时间作为分区的依据。例如Bizdate指的是业务系统产生数据的时间,按照(T+1)加工,一般是每天计算前一天的业务数据。表就会按照这个业务时间来分区,不同的分区就存不同业务系统时间的数据。
在优化表前后测试系统性能时,需要记录每张表的数据同步时间、占用存储大小以及查询性能的详细信息。
工作台
DataWorks按照业务种类组织相关的不同类型的节点,可以更好地以业务为单元、连接多个业务流程进行开发。通过工作空间 > 解决方案 > 业务流程3级结构,全新定义开发流程。
l 工作空间:权限组织的基本单位,用来控制您的开发、运维等权限。工作空间内成员的所有代码均可以协同开发管理。
l 解决方案:您可以自定义组合业务流程为一个解决方案。解决方案之间可以复用相同的业务流程。
l 业务流程:业务的抽象实体,让您能够以业务的视角来组织数据代码开发。业务流程可以被多个解决方案复用。每个节点类型下均支持创建多级子目录,右键单击相应的节点类型,选择新建文件夹即可(注意必须在数据集成/maxcompute这种类型的节点下面见文件夹,其他位置建不会成功)。例如:

工作空间包含两种模式:
l 简单模式工作空间包含的每一个计算引擎实例只能有一套环境,无法区分开发和生产环境,只能进行简单的数据开发,且无法对数据开发流程和表权限进行强控制。简单直观、迭代快,代码提交后(也就是在生产环境形成调度任务,完成运行后,如果所有节点都显示绿色图标,则表示业务流程测试通过),无需发布即可生效。
l 标准模式工作空间包含的每一个计算引擎实例都包含两套环境,分别为开发环境和生产环境。同时,可以基于角色定义用户权限,开发人员仅能操作开发环境中的数据和任务脚本,而运维人员仅能操作生产环境的任务脚本,所有人均无法直接访问生产环境的数据。节点提交成功后,需要进一步单击右上角的发布。
一般的工作流程是:
节点逻辑开发-》配置调度参数-》提交业务流程-》运行业务流程-》临时查询检查结果-》发布业务流程-》生产环境运行任务
菜单
- 最左边的菜单栏
l 数据开发:可以在数据开发模块新建解决方案和业务流程
l 手动业务流程:手动业务流程中创建的所有节点都需要手动触发,无法通过调度执行
l 运行历史:可以在运行历史模块查看最近3天运行过的所有任务记录
l 临时查询:可以在临时查询模块查询您在本地测试代码的实际情况与期望值 是否相符、排查代码错误等
l 公共表:公共表为生产环境的表
l 表管理:可以在表管理模块新建、提交和查询数据表
l 函数列表:可以在函数列表模块查看当前可以使用的函数、函数的分类、函数的使用说明和实例
l 回收站:以在回收站模块恢复或删除节点
l 组件管理:可以在组件管理模块创建组件、使用组件
- 最右边的菜单栏中,有一个版本,如果代码写错了可以回退到上一个版本。
节点介绍
在面板中 解决方案 可以有多个业务流程组成。业务流程是统一管理表、脚本的抽象概念,主要是为了更好的管理代码结构,建议是根据业务场景来定义,但是也可以按照开发概念来定义。
业务流程多个功能节点组成,节点之间的依赖关系就会形成一个网状结构(血缘关系),在业务流程下有
l 数据集成:数据同步的功能操作
l Maxcompute: MaxCompute计算引擎列表。如果有多个计算引擎,此处将显示多个
l 数据服务:提供类似API的数据服务
l 通用:用于业务流程逻辑管理的通用节点,包括虚节点和控制类节点。
l 自定义:
其中Maxcompute做为主要的计算引擎,下面包含
² ODPS SQL:类似SQL的语法,ODPS SQL采用类似SQL的语法,适用于海量数据(TB级)但实时性要求不高的分布式处理场景。
² SQL组件节点:SQL组件是一种带有多个输入参数和输出参数的SQL代码过程模板,SQL代码的处理过程通常是引入一到多个源数据表,通过过滤、连接和聚合等操作,加工出新的业务需要的目标表。
² ODPS Spark:以JAR类型的资源,操作spark
² PyODPS: 可以在DataWorks的PyODPS节点上,直接编辑Python代码,用于操作MaxCompute
² ODPS script: ODPS Script节点的SQL开发模式是MaxCompute基于2.0的SQL引擎提供的脚本开发模式。
² ODPS MR:ODPS MR类型节点可以使用MapReduce Java API编写MapReduce程序来处理MaxCompute中的数据
通用下面包含
² OSS 对象检查:需要依赖该OSS对象传入OSS时,使用OSS对象检查功能
² For-each: 逻辑控制系列
² Do-while: 逻辑控制系列
² 归并节点:逻辑控制系列
² 分支节点:逻辑控制系列
² 赋值节点:上游节点任务的结果提供给下游节点使用
² Shell: Shell语法
² 虚拟节点:不产生任何数据的空跑节点,通常作为业务流程统筹节点的根节点
² 跨租户节点:(我也不懂)
自定义下面包含
² Hologres开发:使用标准的PostgreSQL语句查询分析
² AnalyiticDB Mysql:使用SQL语句对目标AnalyticDB for MySQL数据源进行数据开发
² Datahub Check
² MultiFullMerge
调度配置
在写完ODPS SQL后,点击右边的调度配置,配置调度属性。 调度属性包含
l 时间属性:例如调度周期、重跑属性等,DataWorks根据任务调度配置好的属性自动替换取值,实现在任务调度时间内参数的动态取值。
l 依赖属性:配置节点的上游依赖,表示即使当前节点的实例已经到定时时间,也必须等待上游节点的实例运行完毕,才会触发运行。
参数有以下几种:
l 系统内置变量
l 自定义参数:使用系统的内置参数
l 自定义参数:使用${…}参数
l 自定义参数:使用$[…]参数
l 自定义参数:使用常量参数
系统内置变量:无需手动赋值,参数可以在代码中直接引用。例如:
select po_no
from dwd_hs_master where dt='${bdp.system.bizdate}' ; 包括业务时间参数${bdp.system.bizdate}和定时时间参数${bdp.system.cyctime}。
${bdp.system.bizdate} 格式为yyyymmdd,日常调度实例定时时间的前一天(年月日)。节点每天自动调度实例定时时间年月日减1天。正常调度时,比如:任务定时在14号凌晨执行,那么${bdp.system.bizdate}替换的结果是13号。测试,补数据时,比如:业务日期选择为12号,那么${bdp.system.bizdate}替换的结果是12号。
${bdp.system.cyctime}
格式为yyyymmddhh24miss,日常调度实例定时时间(年月日时分秒)。yyyy表示4位数年份,mm表示2位数月份,dd表示2位数天,hh24表示24小时制的时,mi表示2位数分钟,ss表示2位数秒。正常调度时,比如:任务定时在14号凌晨1点整执行,那么${bdp.system.cyctime}替换的结果是 当天yyyymm140100。测试,补数据时,比如:业务日期选择为12号(任务调度时间配置为每天凌晨1点整执行),那么${bdp.system.cyctime}替换的结果是 所选业务日期的yyyymm130100。
在ODPS SQL节点、离线同步节点、PyODPS节点设置自定义参数的时候,例如
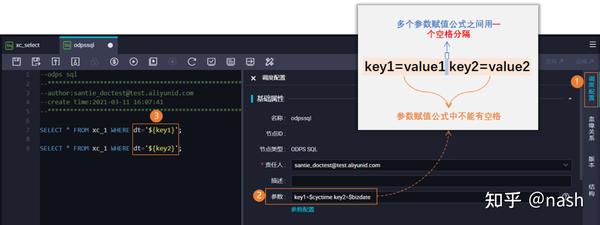

其中key1、key2是自定义的参数名称,value1、value2是系统内置参数(例如$bizdate、$cyctime),注意系统内置参数和系统内置变量是不同的,虽然值一样。
如果是PYODPS节点,在全局变量中增加一个名为args的字典对象:args=['key1'] args=['key2']。其中key1和key2是自定义的参数名称。
${...}参数是基于系统内置参数$bizdate、自定义参数格式的时间参数。通过:
yyyy表示4位的年份,取值为$bizdate的年份。
yy表示2位的年份,取值为$bizdate的年份。
mm表示月,取值为$bizdate的月份。
dd表示天,取值为$bizdate的天。
可以任意组合参数,例如${yyyy}、${yyyymm}、${yyyymmdd}和${yyyy-mm-dd}等(这个没有测试成功)。
临时查询
临时查询用于在本地测试代码的实际情况与期望值是否相符或排查代码错误。临时查询无需提交、发布和设置调度参数。
临时查询下支持新建ODPS SQL、Shell、AnalyticDB for PostgreSQL、AnalyticDB for MySQL和DataLake Analytics节点。
数据集成
数据集成,就是数据同步(例如业务数据库数据同步到MaxCompute数据仓库),有离线批量同步,也有实时同步。同步数据是比较消耗资源的,所以数据集成所用的资源组合数据开发的资源组是分开且分开计费的。
进入常用工作空间后,点击数据集成(应该还有一个同步解决方案),点击数据源管理,可以看到目前已经接入的数据源(参考前面的数据源介绍)。只有管理员会有“新增数据源”的权限,普通开发者只需要了解有哪些数据源可用即可。
在数据开发-》业务流程-》ODS源端_数据同步,是同步各个数据源到ODPS的代码。ODPS就是maxcompute,类似于hive。AnalyticDB是阿里云自主研发的一款实时分析数据库,实时OLAP型数据库,它的对标产品是Apache Kylin等。在数据开发-》业务流程-》CDM_ADS层数据输出到ADB,就是将ODPS里的表再导入到AnalyticDB。
进入datastudio,新建业务流程。
新建一个虚拟节点,作为整个工作流的起始节点(dataworks要求必须要有一个根节点)。点击右边的“调度配置”,在里面点击项目根节点。然后拖入“数据同步”任务,然后用连线的方式把节点的之间关系建立起来。
右边菜单“调度配置”,是将节点任务之间的前后依赖关系。每个节点会默认生成输出名称,基于这些名称,可以在任务之间建立依赖关系。因为必须要有父节点,所以在第一个节点任务的调度依赖栏目,直接点击项目根节点。在调度依赖栏目中,通过设置父节点的输出名称(也可以通过自动解析的方式),就可以建立任务之间的依赖关系,下游任务的输入表是上游任务的产出表。通过看右边菜单的血缘关系,可以看到脚本之间的依赖。
在左边maxcompute->表,右键新建表,来承载前面数据同步过来的数据。通过ddl来完成建表语句,点击发布到开发环境,就把表落到计算引擎里面了。然后就可以开始进入源端和目的表的字段映射。
一般来讲,数据仓库每天计算前一天的业务数据。开发者提交的数据任务都有N个参数,其中bizdate是业务系统的时间,gmtdate是任务实际运行的时间,cyctime是任务定期运行的时间。在配置同步任务的时候,数据源通过“数据过滤条件”使用${bizdate}来筛选数据完成数据增量进入数据仓库。
点击提交,就开始执行同步任务了。
ODPS SQL
最常用的节点,更多信息可以参考https://help.aliyun.com/document_detail/27860.html
ODPS SQL采用类似SQL的语法,完成数据的计算任务。适用于海量数据(TB级)但实时性要求不高的分布式处理场景。提交任务后,点击开发环境的冒烟测试,需要填 业务日期。当冒烟测试通过后,就可以点击上方的发布至生产环境。管理员核查代码后,就可以打包发布。
右上方的任务发布,让管理员来复核代码,没问题就可以发布到生产环境。在运维中心,可以看到所有提交的任务。菜单中的周期实例,可以对已运行任务进行日志检查,查看出错原因。测试实例,是用来测试任务用的。补数据,是当前面任务跑失败后重新再补数,也可以具体看某一个具体节点的日志。
查询表
如果不想指定特定的分区,通过设置fullcan可以查询所有分区下的记录
set odps.sql.allow.fullscan=true;
select * from tmp_meta_fields_value; 建表
create table if not exists sale_detail
(
shop_name string,
customer_id string,
total_price double
)
partitioned by (sale_date string,region string);-- 创建一张分区表sale_detail
drop table if exists dwd_renewal;
create table dwd_renewal
(
id BIGINT comment '辅助字段id',
policy_no STRING comment 'XXXX',
policy_status STRING comment 'XXXX',
premium DOUBLE comment 'XXXX',
expiry_date STRING comment 'XXXX'
)
COMMENT '明细表'
PARTITIONED BY
(dt STRING )
LIFECYCLE 7;只是复制表结构,没有插入数据
drop table if exists tmp_zy;
create table if not exists tmp_zy like ods_group_policy;
alter table ods_group_policy add columns(rno BIGINT );只是复制表结构(没有分区),没有插入数据
-- 为了不要多次跑,建立临时表
drop table if exists tmp_zy_policy;
create table if not exists tmp_zy_policy as select * from ods_group_policy limit 0;
-- 作为单独一步提交,否则会报错
alter table tmp_zy_policy add columns(rno BIGINT);在数据地图里面,可以快速复制已知表的表结构


上传数据
右键单击MaxCompute,选择新建 > 表,单击DDL模式,输入建表语句。
在数据开发页面,单击导入图标,根据数据导入向导对话框,完成上传操作。
https://help.aliyun.com/document_detail/56584.html
写表
set odps.sql.allow.fullscan=true;
insert overwrite table result_table2 select education, count(marital) as num, credit from bank_data_pt where housing = 'yes' and marital = 'single'group by education, credit;完全更新表,如果只是插入 不要写overwrite
insert overwrite table dwd_renewal_policy partition (dt='${bdp.system.bizdate}')
select
ROW_NUMBER() OVER( ORDER BY 1) as id
,policy_no
,policy_status
,substr(apply_time,1,10) as apply_time
,substr(effective_time,1,10) as effective_time
from renewal_policy
where dt='${bdp.system.bizdate}'
and expiry_date>='2020-10-01 00:00:00'
and expiry_date<=dateadd(expiry_date,90,'dd')
;导出数据
一种方法是通过ODPS SQL查询,结果集下载,但是有记录条数的限制。
一种方法是安装maxcompute客户端,参考
https://help.aliyun.com/document_detail/27971.html
https://help.aliyun.com/document_detail/27810.html?spm=5176.doc27809.6.572.aw24p5
常用函数
阿里提供了很多内建函数
https://help.aliyun.com/document_detail/48976.html
https://help.aliyun.com/document_detail/48975.html 聚合函数 特别有用
https://help.aliyun.com/document_detail/48973.html 字符串函数,有一些正则函数
https://c.runoob.com/front-end/854 正则表达式
Now()这是个bug,兼容mysql没做好,会导致随机出错, 改成to_date(getdate())就行了
if(max(b.end_update_date) is not null,max(b.end_update_date), to_date(now(),'yyyy-mm-dd hh:mi:ss.ff3')) as end_update_date, 改成
if(max(b.end_update_date) is not null,max(b.end_update_date), getdate()) as end_update_date,其他常用函数
toupper(""aBcd"") = ""ABCD"" // 转化为大写
若trans_date = 2005-02-28 00:00:00, dateadd(transdate, 1, 'mm') = 2005-03-28 00:00:00 // dateadd()时间的加减
to_date('20080718', 'yyyymmdd') = 2008-07-18 00:00:00 // 字符串转换成时间
to_char('2008-07-18 00:00:00', 'yyyymmdd') = '20080718' // 时间转换成字符串
datetrunc(2011-12-07 16:28:46, 'month') = 2011-12-01 00:00:00 // 时间的截取
datepart('2013-06-08 01:10:00', 'mm') = 6 // 返回时间的部分内容
若start = 2005-12-31 23:59:59,end = 2006-01-01 00:00:00,datediff(end, start, 'dd') = 1 // 返回时间差
round(125.315, 2) = 125.32 // 截取有效位数,四舍五入
COALESCE(da1.account_id, da2.account_id, da3.account_id, -1) AS account_id,
,TO_CHAR(active_time,'yyyy-mm-dd') as active_date -- 活跃日期
and to_date(a.effective_date,'yyyy-mm-dd')>=dateadd(datetrunc(getdate(),'dd'),-2,'mm')
and to_date(a.effective_date,'yyyy-mm-dd')<dateadd(datetrunc(getdate(),'dd'),-1,'mm')
转变变量类型
, CAST(outer_account_id AS BIGINT) AS mapping_account_id
,DATEDIFF(GETDATE(),to_date(birthday,'yyyy-mm-dd') ,'year') as insurant_age
看分位数
select percentile_approx(ratio, array(0.1,0.2,0.3,0.4, 0.5,0.6,0.7,0.8,0.9,1.0),1000) as percent_value
from tmp_zy_group ;
解析json格式
,get_json_object(get_json_object(get_json_object(t4.extra,'$.pay'),'$.bank'),'$.label') as bank
select * from
(select
id,enquiry_id,code
from
(select *,
from_json(get_json_object(detail,'$.products[*].code'),'array<string>') as code_array,
get_json_object(detail,'$.products[*].amount') as amount
from ods_plan
where dt='${bdp.system.bizdate}' and is_deleted='N' )
lateral view explode(code_array) t2 as code
) a
left join
(select
id,enquiry_id,amount
from
(select *,
from_json(get_json_object(detail,'$.products[*].amount'),'array<double>') as amount_array
from ods_e001_iyb_enquiry_common_plan
where dt='${bdp.system.bizdate}' and is_deleted='N' )
lateral view explode(amount_array) t2 as amount
) b on a.id = b.id and a.enquiry_id = b.enquiry_id
@plan_detail :=
select id,enquiry_id,array_item,
get_json_object(concat('{',array_item,'}'),'$.amount') as amount,
get_json_object(concat('{',array_item,'}'),'$.code') as code,
get_json_object(concat('{',array_item,'}'),'$.premium') as premium
from
(select *,
regexp_replace(regexp_replace(get_json_object(detail,'$.products[*]'),'\\[\\{',''),'\\}\\]','') as products_array
from ods_plan
where dt='${bdp.system.bizdate}' and is_deleted='N' )
lateral view explode(split(products_array,'\\}\\,\\{')) t2 as array_item ;
返回第一个非NULL的值
,COALESCE(d.lng_plc_surrender_commission_between_30d_cnt,0) as lng_plc_surrender_commission_between_30d_cnt 行列转换
一行数据转多行
https://help.aliyun.com/document_detail/293597.html#section-7rk-9a6-0la
列转行
select tbl_name, fld_name, concat_ws(',',collect_list(fld_value_cnt)) from
(select tbl_name, fld_name, concat_ws(':',fld_value,fld_cnt) as fld_value_cnt
from tmp_meta_fields_value)添加序号
SELECT item_sku,
ROW_NUMBER() OVER(PARTITION BY 1 order by item_sku) AS numsFROM bi_item;去重
select * from
(select *,
ROW_NUMBER() OVER(PARTITION BY policy_no ORDER BY gmt_created DESC) AS rno
from ods_group_table
where dt = '20200701' and is_deleted='N' ) temp
where rno = 1;半连接
left anti join。当join条件不成立时,返回左表中的数据。如果左表中满足指定条件的某行数据没有在右表中出现过,则此行保留在结果集中。
select * from @cases_open a left anti join @cases_closed b on a.policy_no = b.policy_no and a.accident_date = b.accident_date注意: left anti join on的条件中 不要写 应该写在where里面的条件
按照条件衍生
使用case when语句
SELECT *
, CASE
WHEN item_price < 10 THEN '0-10'
WHEN item_price < 100 THEN '10-100'
ELSE '100-300'
END AS waveFROM bi_crm_order;
count(distinct case when top_category='XX' then po_no else null end ) as P_his_cnt 使用if else 语句
SELECT
if(length(style)>0,style,""),
FROM tmp_item;
,if(birthday is not null ,datediff(GETDATE(),to_date(birthday,'yyyy-mm-dd'), 'yyyy'),null) as in_age -- 年龄ODPS Script
我最喜欢的节点之一,参考https://help.aliyun.com/document_detail/139140.html
ODPS Script节点的SQL开发模式是MaxCompute基于2.0的SQL引擎提供的脚本开发模式。
本质上是SQL语法,但是添加了“变量赋值”的功能。
适合用于:
- 逻辑复杂,需要层层嵌套子查询或者多次关联不同表的场景
- 将复杂问题分解,针对性的完成各个子表的脏数据处理和变量加工后,再组合成大表
组件
最左边的菜单 -》组件管理-》新建组件
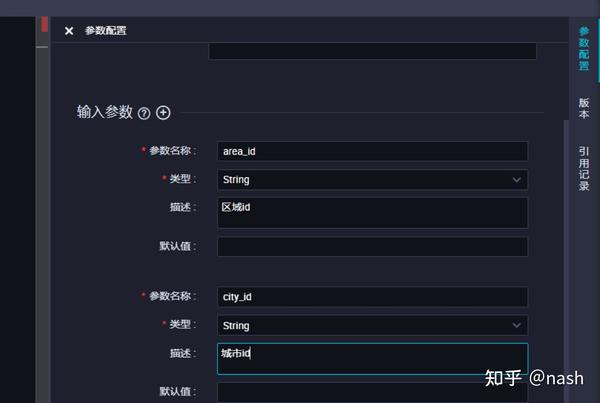
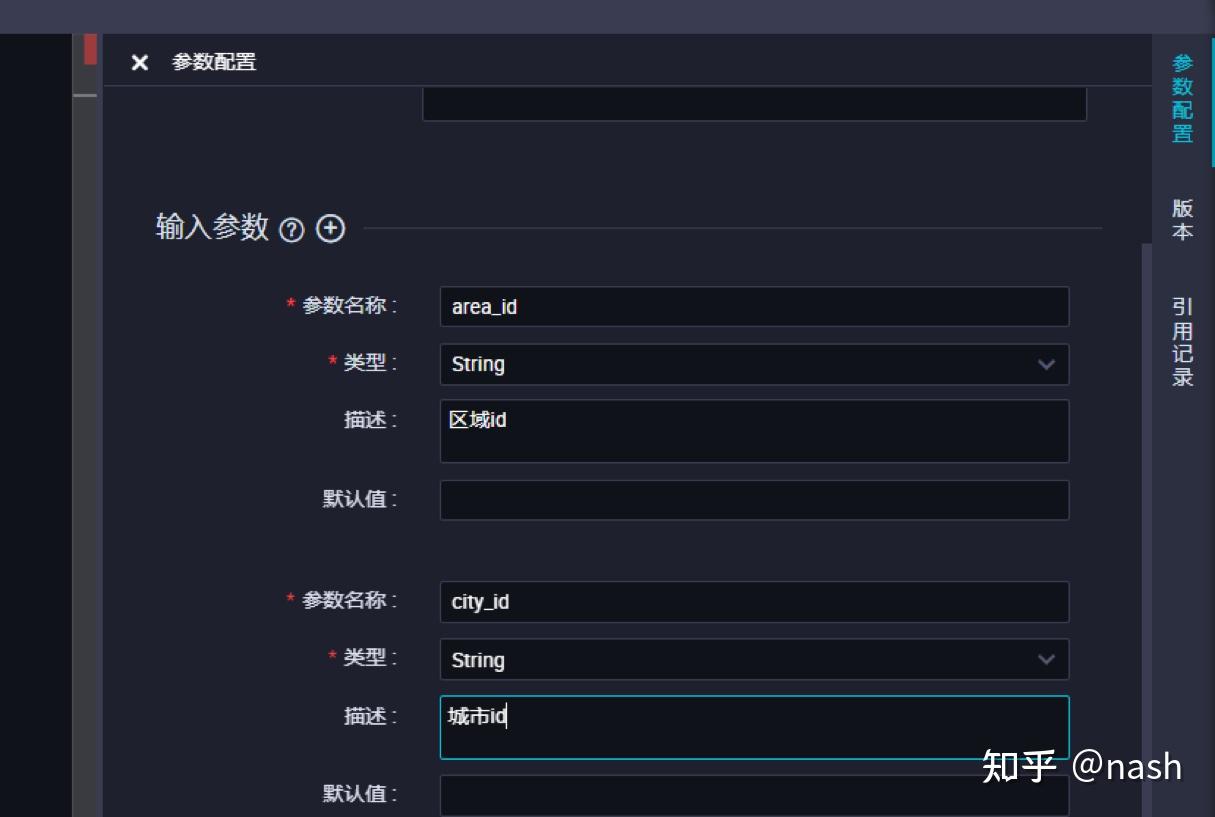
一个组件就和一个函数的定义一样,由输入参数、输出参数和组件代码过程构成。参数类型分为表(table)和字符串(string)类型,在代码中用@@{}来完成引用。
右边菜单栏,设置输入和输出参数。
INSERT OVERWRITE TABLE @@{myoutput} PARTITION (pt='${bizdate}')
SELECT r3.area_id,
r3.city_id,
r3.order_amt,
r3.rank
from @@{myinputtable}PyODPS
我最喜欢的节点之一。
为 MaxCompute 对象提供了 Python 端的操作接口,同时,对于熟悉 Pandas 的用户来说,它提供了 DataFrame API 来用类似Pandas 的接口进行大规模数据分析以及处理,并能够方便的将 MaxCompute 的分布式 DataFrame 向本地 Pandas DataFrame 转换。可以通过PyODPS完成包括创建表、创建表的Schema、同步表更新、获取表数据、删除表、表分区操作。
DataWorks 中的 PyODPS 节点是一个资源非常受限的客户端运行容器,内置了 PyODPS 包以及必要的 Python 环境,并不使用MaxCompute 资源,有较强的内存限制(日志中如果有Got killed报错)。
正确的使用方式,是使用 PyODPS DataFrame 接口来完成数据处理。
DataWorks 中的 PyODPS 节点也是一个资源非常受限的客户端运行容器,内置了 PyODPS 包以及必要的 Python 环境,并不使用 MaxCompute 资源,有较强的内存限制。因此合理利用 PyODPS 提供的分布式 DataFrame 功能,将主要的计算提交到MaxCompute 分布式执行而不是在 PyODPS 客户端节点下载处理,是正确使用 PyODPS 的关键。PyODPS 提供了 to_pandas 接口,可以直接将 MaxCompute 数据转化成 Pandas DataFrame 数据结构,这个接口很受欢迎。但这个接口只应该被用于获取小规模数据做本地开发调试使用,而不是用来大规模处理数据。使用这个接口会触发下载行为,将位于 MaxCompute 中的海量数据下载到本地,如果后续操作的都是本地的 DataFrame,则丧失了 MaxCompute 的大规模并行计算能力。而且,数据量稍大,单机内存就很容易产生 OOM。
更多参考
https://help.aliyun.com/document_detail/90688.htm PyODPS快速入门
https://developer.aliyun.com/article/782779 如何确定运行在服务端还是客户端
https://developer.aliyun.com/article/745029 高效使用 PyODPS 最佳实践
https://developer.aliyun.com/article/591508 自定义函数中使用pandas、scipy和scikit-learn
https://help.aliyun.com/document_detail/90716.html 使用自定义函数及Python第三方库
https://developer.aliyun.com/article/138752 PyODPS开发中的最佳实践,后端进行高效本地 debug
https://help.aliyun.com/document_detail/145053.htm PyODPS节点实现避免将数据下载到本地
https://blog.csdn.net/weixin_34318326/article/details/90195822 利用PyODPS 获取项目的元信息
https://blog.csdn.net/ManWZD/article/details/109329021 使用 PyODPS 统计 ODPS 空间内的表数据信息
代码调试
代码完成以后,可以选择部分代码或者不选择(全部运行),点击运行,运行结束后,可以在下方的运行日志中看到运行结果。
本地使用pycharm,可以更好的完成代码的交互式调试。
先安装
pip install setuptools>=3.0
pip install requests>=2.4.0
pip install greenlet>=0.4.10 # 可选,安装后能加速 Tunnel 上传
pip install cython>=0.19.0 # 可选,不建议 Windows 用户安装
然后安装包pyodps
参数设置
Dataworks上默认未开启instance tunnel,即instance.open_reader默认使用Result接口(最多一万条记录)。如果需要迭代获取全部数据,则需要关闭limit限制。
options.tunnel.use_instance_tunnel = True
options.tunnel.limit_instance_tunnel = False # 关闭limit限制,读取全部数据。如果不想全局关闭,可以指定某一次读取实例关闭
with instance.open_reader(tunnel=True, limit=False) as reader:# 本次open_reader使用Instance Tunnel接口,且能读取全部数据。在全局变量中有一个名字为args的dict,调度参数可以在此获取。例如,在节点基本属性 > 参数中设置ds=${yyyymmdd},在代码中可以通过 print('ds=' + args['ds']) 获得。
运行sql时,可以通过参数hints来设置运行参数,例如设定一个map的最大数据输入量,单位M。
o.execute_sql('select * from pyodps_iris', hints={'odps.sql.mapper.split.size': 16})表操作
首先要创建表的schema,例如
from odps.models import Schema, Column, Partition
columns = [Column(name='num', type='bigint', comment='the column'),
Column(name='num2', type='double', comment='the column2')]
partitions = [Partition(name='pt', type='string', comment='the partition')]
schema = Schema(columns=columns, partitions=partitions)
然后通过schema创建表
table = o.create_table('my_new_table', schema)
一般来讲,表都是分区的,但也是可以不分区的,那么建立schema的时候不要输入partitions参数即可。
读入表,
pt_df = DataFrame(o.get_table('partitioned_table').get_partition('pt=20171111'))写入表,可以用write_table方法,也可以用open_writer的方法。
partition = '%s=%s' %(partitions[0].name, table_name)
to_tbl.delete_partition(partition, if_exists=True)
odps.write_table(to_table, records, partition=partition, create_partition=True)删除表,使用delete_table方法。
SQL查询
如果sql语句很长有多行,则用 三个引号 来讲sql语句包含起来
然后使用execute_sql()和run_sql()方法可以执行SQL语句
读取sql执行结果时,
with o.execute_sql('select * from table_name').open_reader() as reader:
for record in reader:
# 处理每一个record。
print record["userid"],record["job"],record["education"]
print record[0],record[1],record[2]
data_count = reader[0][0] # 取第一行数据的第一个字段聚合操作
print(datatable.describe().execute())如果sql中要带参数,用如下方法 args[‘dt’]
sql = " create table ads_groupzy as \
select * \
from \
(select \
id \
,po_no \
,appno \
,company \
,ROW_NUMBER() OVER(PARTITION BY po_no ORDER BY gmt_created DESC) AS rno \
from ods_group \
where dt =" + args['dt'] + " \
and is_deleted='N' and \
policy_no is not null and policy_no != '' and \
policy_type = 4 and policy_status = 3) temp \
where rno = 1 "
o.execute_sql(sql)
sql = '''
select *
from tmp_zy_selected_channel
'''建立DataFrame
PyODPS提供了DataFrame API,它提供了类似Pandas的接口,但是能充分利用MaxCompute的计算能力。同时能在本地使用同样的接口,用Pandas进行计算。
在使用 DataFrame 时,需要了解三个对象上的操作:Collection(DataFrame) ,Sequence,Scalar。 这三个对象分别表示表结构(或者二维结构)、列(一维结构)、标量。
需要注意的是,这些对象仅在使用 Pandas 包转化会包含实际数据, 而在 ODPS 表上创建的对象中并不包含实际的数据,而仅仅包含对这些数据的操作,实质的存储和计算会在 ODPS 中进行。
DataFrame上的所有操作并不会立即执行,只有当显式调用execute方法,或者调用立即执行的方法时(内部调用的也是execute),才会执行这些操作。
# 从ODPS表创建DataFrame。
iris = DataFrame(o.get_table('pyodps_iris'))
iris2 = o.get_table('pyodps_iris').to_df() # 使用表的to_df方法。
# 从MaxCompute分区创建DataFrame。
pt_df = DataFrame(o.get_table('partitioned_table').get_partition('pt=20171111'))
pt_df2 = o.get_table('partitioned_table').get_partition('pt=20171111').to_df() # 使用分区的to_df方法
# 从Pandas DataFrame创建DataFrame。
import pandas as pd
import numpy as np
df = DataFrame(pd.DataFrame(np.arange(9).reshape(3, 3), columns=list('abc')))
# ResultFrame可以迭代取出每条记录。
result = iris.head(3)
for r in result:
print(list(r))
# 保存执行结果为MaxCompute表
iris2 = iris[iris.sepalwidth < 2.5].persist('pyodps_iris2')
df.persist('table_name', odps=o
#保存执行结果为Pandas DataFrame
#使用to_pandas方法,如果wrap参数为True,将返回PyODPS DataFrame对象。
iris[iris.sepalwidth < 2.5].to_pandas()
#缓存中间Collection计算结果,部分Collection被多处使用的场景。
cached = iris[iris.sepalwidth < 3.5].cache()
#异步和并行执行
from odps.df import Delay
delay = Delay() # 创建Delay对象。
df = iris[iris.sepal_width < 5].cache() # 有一个共同的依赖。
future1 = df.sepal_width.sum().execute(delay=delay) # 立即返回future对象,此时并没有执行。
future2 = df.sepal_width.mean().execute(delay=delay)
future3 = df.sepal_length.max().execute(delay=delay)
delay.execute(n_parallel=3) # 并发度是3,此时才真正执行缺失值处理
policy_bytime = policy_bytime.fillna(value=0,subset=['cnt','cnt_7d','cnt_1m','cnt_3m'])数据汇总
# 使用ODPS dataframe的 pivot透视表接口,返回resultframe
summary = online_mg.pivot_table(values='is_acc',
rows=['package','product'],
aggfunc='sum').execute()# 使用groupby
summary = cases.groupby('day').agg(cnt = cas.m_day.count(),
cnt_7d = cas.cnt_7d.sum(),
cnt_1m = cas.ccnt_1m.sum(),
cnt_3m = cas.cnt_3m.sum())
累计汇总
summary = summary.sort('claim_day',ascending=True) accu_grouped = summary['claim_day', summary.groupby('company_name').sort('claim_day').cases_cnt.cumcount().rename('cases_cnt') ]自定义函数
https://help.aliyun.com/document_detail/94159.html 在PyODPS节点中调用第三方包
https://help.aliyun.com/document_detail/124839.html PyODPS节点实现结巴中文分词
https://help.aliyun.com/document_detail/90716.html 使用自定义函数及Python第三方库
https://help.aliyun.com/document_detail/189752.html Python UDF使用第三方包
https://help.aliyun.com/document_detail/126936.html PyODPS使用第三方包
MaxCompute大部分开发都可以通过SQL语句实现,但对于复杂的业务场景以及自定义函数(UDF)都需要使用Python。
目前python节点已经预装各种包,可以使用import看看会不会报错判断包存在不存在。
DataFrame自定义函数需要提交到MaxCompute执行。
由于Python沙箱限制,自定义函数如果要用到第三方库只支持纯粹Python库以及Numpy,因此不能直接使用Pandas。DataWorks中执行的非自定义函数代码可以使用平台预装的Numpy和Pandas。不支持其他带有二进制代码的三方包。MaxCompute内置的Python 3环境使用Numpy包。MaxCompute内置的Python 2环境默认安装了Numpy,不需要手动上传Numpy包。通过Python 3 UDF使用Numpy包的步骤如下:
n 在PyPI页面的Download files区域,单击文件名后缀cp37-cp37m-manylinux1_x86_64.whl的Numpy包进行下载
n 修改下载的Numpy包后缀为ZIP格式
n 以archive方式上传,whl后缀的包需要重命名为zip
o.create_resource('numpy.zip', 'archive', file_obj=open('D:\\python_project\\source\\numpy-1.21.1-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.zip', 'rb'))
n #全局配置使用到的三方库如下
options.df.libraries = ['numpy.whl']
n #如果自定义函数用到第三方库,需要使用该参数
options.sql.settings = {'odps.isolation.session.enable': True}
从调试的情况来看,在dataworks上 pyodps2节点会更加稳定,但是本地用pycharm 用python2的报错信息不完整。
如果需要使用第三方包,需要上传资源,操作起来比较麻烦。
在临时查询中使用list resources; 可以查看目前上传的资源包。语句o.delete_resource('six.whl') 删除资源。
在本地调试时,使用自定义函数,注意对自定义函数修改后,有的时候要重启session才会生效。
对某一列数据使用自定义函数,使用map方法。如果map前后,Sequence的类型发生了变化,则需要显式指定map后的类型。
policy['insure_day'] = policy['insure_date'].map(lambda x: int(str(x)[0:10].replace('-','')),'int')
group_holder['ratio'] = group_holder['holder'].map(lambda x:string_similar(x,company),'float')对一行数据使用自定义函数,可以使用apply方法。参数axis的值必须设为1,表示对行进行操作。apply的自定义函数接收一个参数,参数为上一步Collection的一行数据。使用@output约定自定义函数返回的字段和类型。
# 生成一个 时间到天的变量
@output(['day'], ['int'])
def handle(row):
date_trunc = 0
if row.report_date is not None:
date_trunc = row.report_date.year *10000 + row.report_date.month * 100 + row.report_date.day
return date_trunc
cases['c_day'] = cases.apply(handle, reduce=True,axis=1)
@output(['earned'], ['float'])
def cal_earned(row):
earned = row.premium
days = (row.expiry_date - row.effective_date).days
to_point_days = (datetime.strptime(str(time_point),'%Y%m%d') - row.effective_date).days
if policy_days >0 and to_point_days <days:
earned = row.final/days * to_point_days
return earned
policy_b4_time['earned'] = policy_b4_time.apply(cal_earned, reduce=True,axis=1) 通过Function Studio开发UDF
如果用python开发,可以把函数包装成一个单独的文件,上传成资源。
https://help.aliyun.com/document_detail/90694.htm https://help.aliyun.com/document_detail/94159.html
而后在调用的地方引入该文件
sys.path.append(os.path.dirname(os.path.abspath('email_utility.py')))
from email_utility import EmailUtility发邮件
https://help.aliyun.com/document_detail/113022.html
DATAWORKS-任务运维
运维
在运维中心查看您的任务和实例,并对展示的任务进行测试、补数据等操作
进入周期实例,查看具体任务,点击运行诊断,具体看所有任务的运行情况、资源调度情况,从而定位具体出错的原因。
节点开发完成以后,有三种调度任务的方式:测试运行、补数据和周期运行。
l 测试运行:手动触发方式。仅需要确认单个节点的定时情况和运行。点击冒烟测试,或者进入周期任务运维 > 周期任务>具体节点的测试。
l 补数据运行:需要从某个根节点开始重新执行数据分析计算
l 周期运行:系统自动触发方式。提交成功的节点,调度系统在第二天0点起会自动触发当天不同时间点的运行实例,并在定时时间达到时检查各实例的上游实例是否运行成功。
在运维中心页面,单击左侧导航栏中的周期任务运维 > 周期实例,选择业务日期或运行日期等参数,搜索write_result节点对应的实例后,右键查看实例信息和运行日志。
在左侧导航栏中的运行历史,切换至运行历史面板,可以看到之前所有运行脚本的日志。
发布
在严谨的数据开发流程下,开发者通常会在用于开发的项目内,完成代码开发、流程调试、依赖属性和周期调度属性配置后,再提交任务至生产环境调度运行。
您可以克隆并提交任务至用于生产的工作空间,即通过简单模式工作空间(用于开发)结合简单模式工作空间(用于生产),实现简单模式工作空间内开发环境和生产环境隔离。
提交业务流程后,表示任务已进入开发环境。由于开发环境的任务不会自动调度,您需要发布配置完成的任务至生产环境。在业务流程的编辑页面,单击工具栏中的发布图标,进入发布页面。选择待发布任务,单击添加到待发布。
DATAWORKS-数据质量
数据质量是支持多种异构数据源的质量校验、通知及管理服务的一站式平台。
数据质量依托DataWorks平台,为您提供全链路的数据质量方案,包括数据探查、对比、质量监控、SQL扫描和智能报警等功能。
l 针对已有的表进行监控规则配置,配置完成后进行试跑,验证该规则是否适用。
l 试跑成功后,将该规则和调度任务进行关联。在监控规则配置完成且试跑成功的情况下,您需要将表和其产出任务进行关联,以便每次表的产出任务运行完成后,都会触发数据质量规则的校验,以保证数据的准确性。
l 关联调度后,每次调度任务代码运行完成,都会触发数据质量的校验规则,以提升任务准确性。数据质量支持设置规则订阅,您可以针对重要的表及其规则设置订阅,设置订阅后会根据数据质量的校验结果进行告警,从而实现对校验结果的跟踪。