
超轻量OCR系统PP-OCRv3技术解读

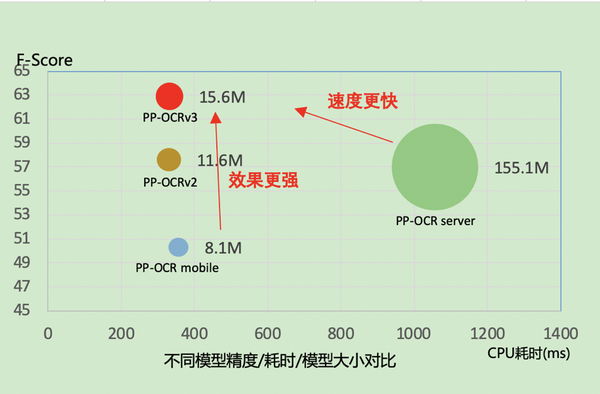
PP-OCR是PaddleOCR团队自研的超轻量OCR系统,面向OCR产业应用,权衡精度与速度。近期,PaddleOCR团队针对PP-OCRv2的检测模块和识别模块,进行共计9个方面的升级,打造出一款全新的、效果更优的超轻量OCR系统:PP-OCRv3。
从效果上看,速度可比情况下,多种场景精度均有大幅提升:
- 中文场景,相比于PP-OCRv2中文模型提升超5%;
- 英文数字场景,相比于PP-OCRv2英文数字模型提升11%;
- 多语言场景,优化80+语种识别效果,平均准确率提升超5%。

一些可视化效果图如下:


全新升级的PP-OCRv3的整体的框架图(粉色框中为PP-OCRv3新增策略)如下图。检测模块仍基于DB算法优化,而识别模块不再采用CRNN,更新为IJCAI 2022最新收录的文本识别算法SVTR (论文名称:SVTR: Scene Text Recognition with a Single Visual Model,https://arxiv.org/abs/2205.00159 ),并对其进行产业适配。
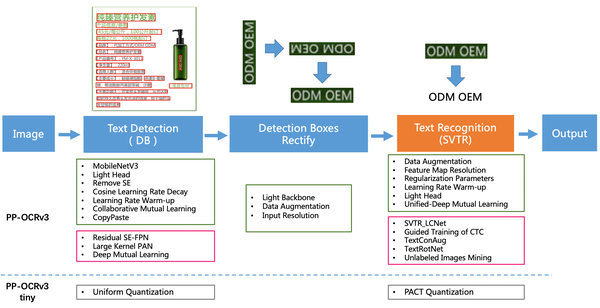
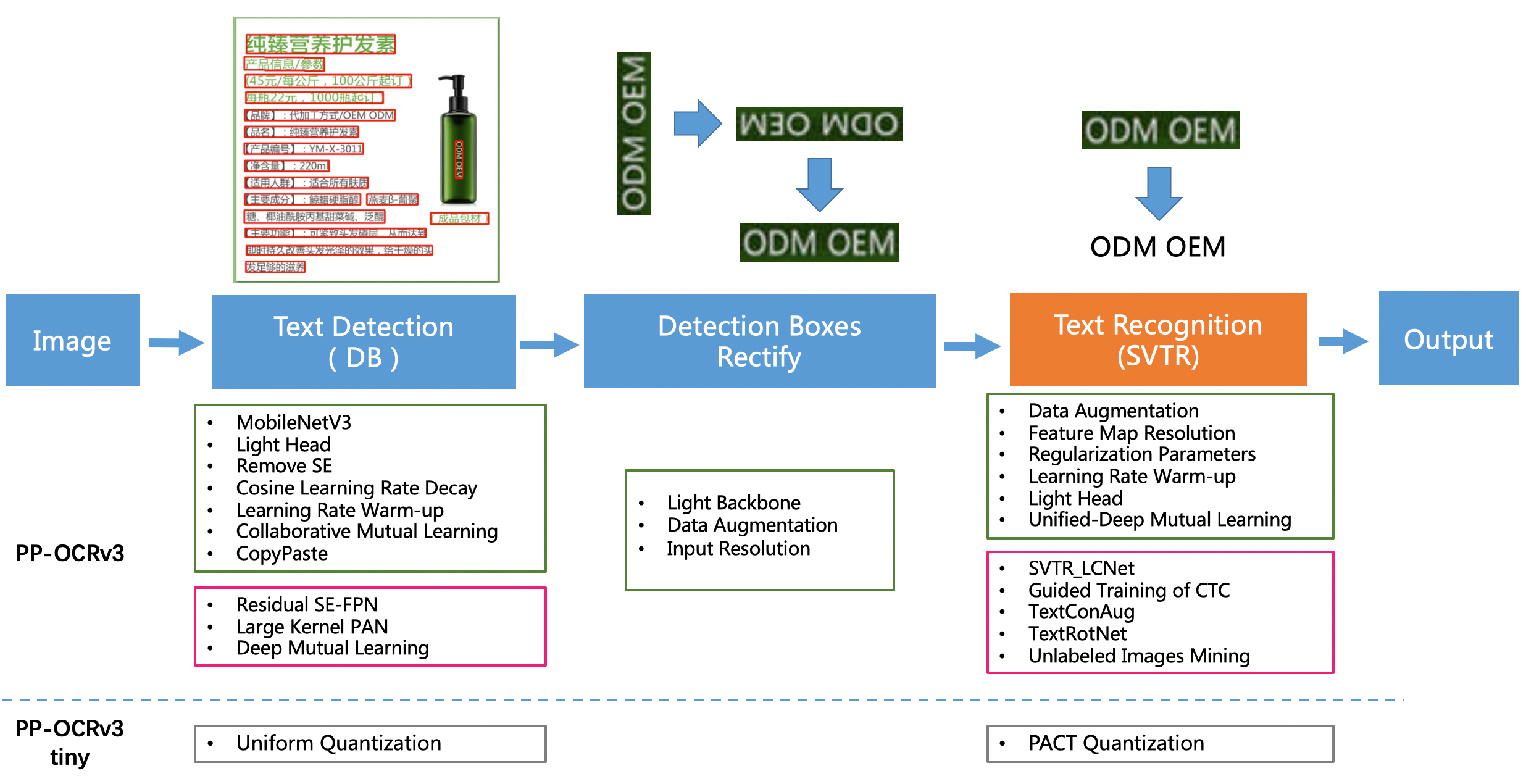
具体的优化策略包括:
检测模块
- LK-PAN:大感受野的PAN结构
- DML:教师模型互学习策略
- RSE-FPN:残差注意力机制的FPN结构
识别模块
- SVTR_LCNet:轻量级文本识别网络
- GTC:Attention指导CTC训练策略
- TextConAug:挖掘文字上下文信息的数据增广策略
- TextRotNet:自监督的预训练模型
- UDML:联合互学习策略
- UIM:无标注数据挖掘方案
一、检测模块优化策略解读
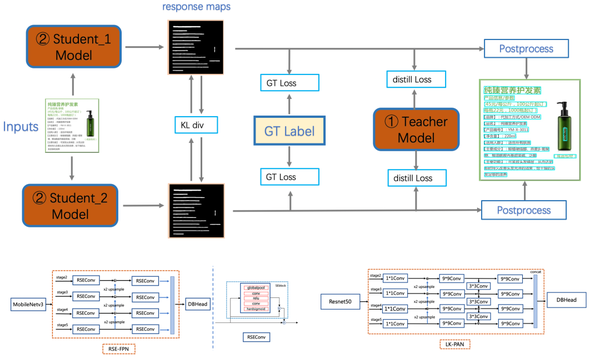
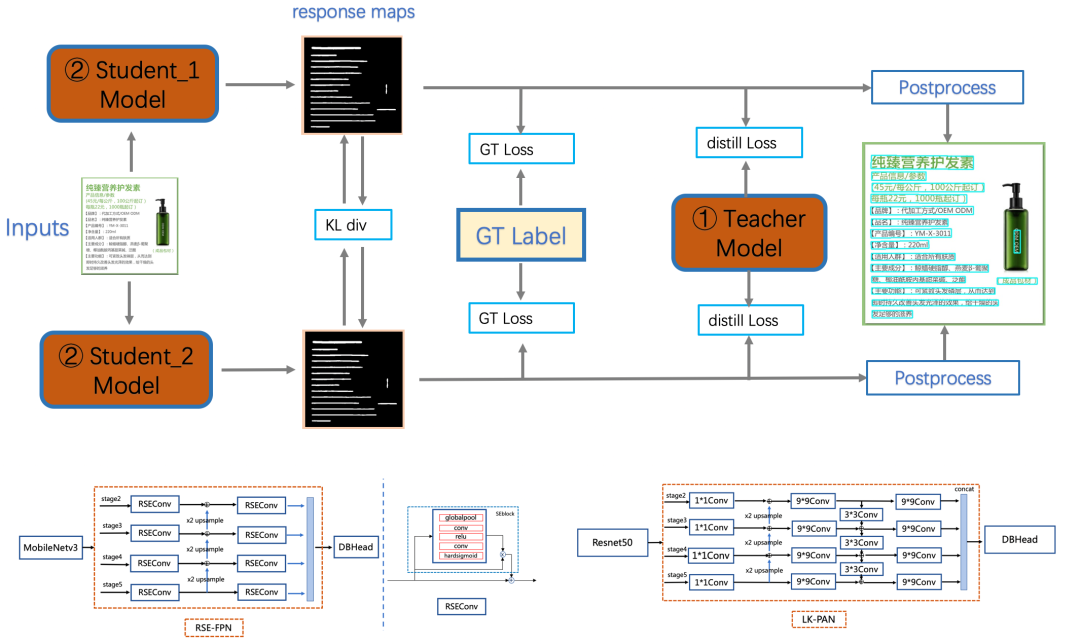
PP-OCRv3检测模块对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了①传统的Teacher指导Student的标准蒸馏与 ②Students网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。消融实验如下表所示。
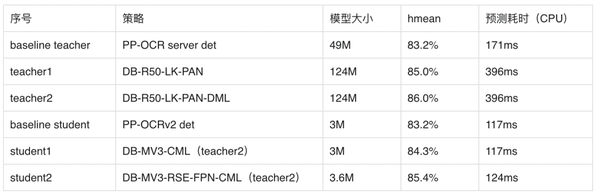

测试环境:Intel Gold 6148 CPU,预测时开启MKLDNN加速。
1.LK-PAN:大感受野的PAN结构
LK-PAN (Large Kernel PAN) 是一个具有更大感受野的轻量级PAN结构,核心是将PAN结构的path augmentation中卷积核从3*3改为9*9。通过增大卷积核,提升特征图每个位置覆盖的感受野,更容易检测大字体的文字以及极端长宽比的文字。使用LK-PAN结构,可以将教师模型的hmean从83.2%提升到85.0%。
2.DML:教师模型互学习策略
DML 互学习蒸馏方法,通过两个结构相同的模型互相学习,可以有效提升文本检测模型的精度。教师模型采用DML策略, hmean从85%提升到86%。将PP-OCRv2中CML的教师模型更新为上述更高精度的教师模型,学生模型的hmean可以进一步从83.2%提升到84.3%。
3.RSE-FPN:残差注意力机制的FPN结构
RSE-FPN(Residual Squeeze-and-Excitation FPN)引入残差结构和通道注意力结构,将FPN中的卷积层更换为带有残差结构的通道注意力结构的RSEConv层,进一步提升特征图的表征能力。进一步将PP-OCRv2中CML的学生模型的FPN结构更新为RSE-FPN,学生模型的hmean可以进一步从84.3%提升到85.4%。
二、识别模块优化策略解读
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。直接将PP-OCRv2的识别模型,替换成SVTR_Tiny,识别准确率从74.8%提升到80.1%(+5.3%),但是预测速度慢了将近11倍,CPU上预测一条文本行,将近100ms。因此,如下图所示,PP-OCRv3采用如下6个优化策略进行识别模型加速,消融实验如下表所示。
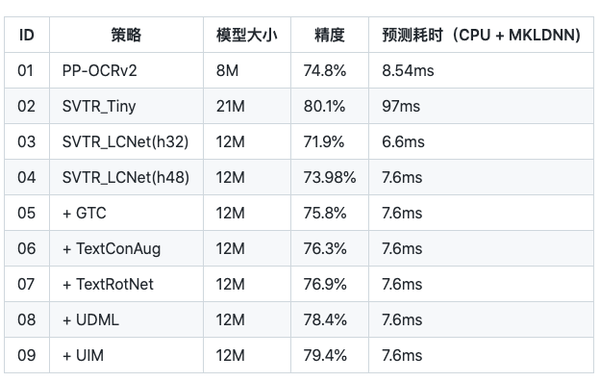

注:测试速度时,实验01-03输入图片尺寸均为(3,32,320),04-08输入图片尺寸均为(3,48,320)。在实际预测时,图像为变长输入,速度会有所变化。测试环境:Intel Gold 6148 CPU,预测时开启MKLDNN加速。
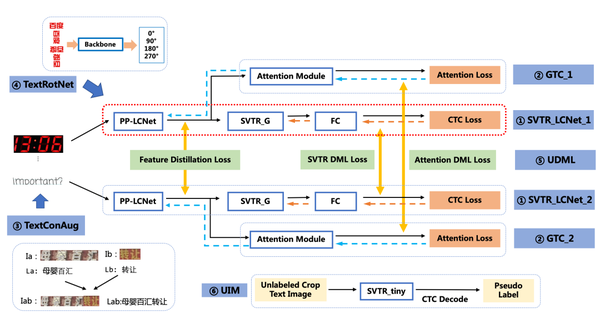
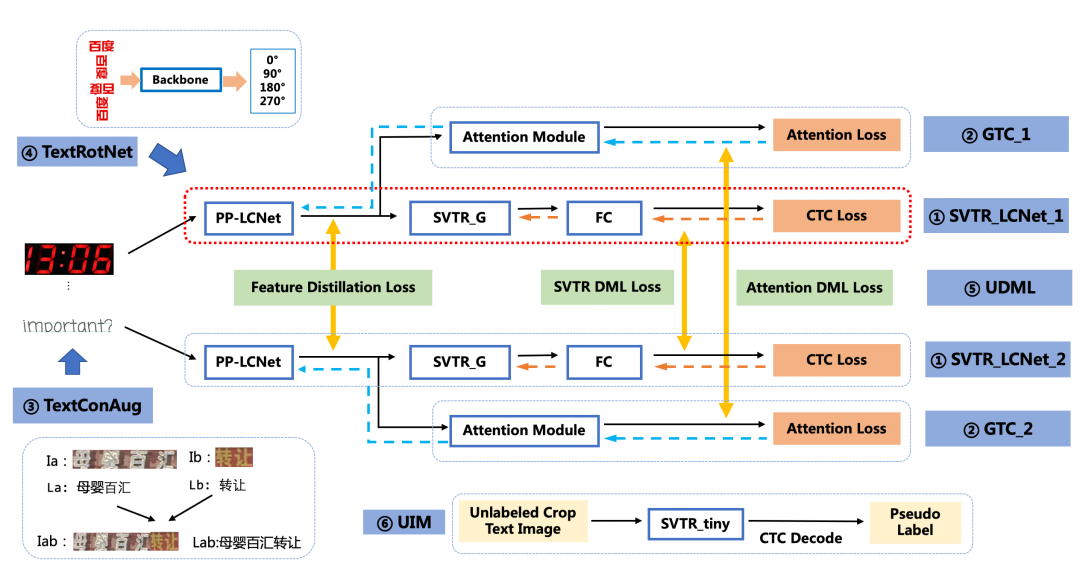
1.SVTR_LCNet:轻量级文本识别网络
SVTR_LCNet是针对文本识别任务,将Transformer网络和轻量级CNN网络PP-LCNet 融合的一种轻量级文本识别网络。使用该网络,并且将输入图片规范化高度从32提升到48,预测速度可比情况下,识别准确率达到73.98%,接近PP-OCRv2采用蒸馏策略的识别模型效果。
2.GTC:Attention指导CTC训练策略
GTC(Guided Training of CTC),利用Attention指导CTC训练,融合多种文本特征的表达,是一种有效的提升文本识别的策略。使用该策略,识别模型的准确率进一步提升到75.8%(+1.82%)。
3.TextConAug:挖掘文字上下文信息的数据增广策略
TextConAug是一种挖掘文字上下文信息的数据增广策略,可以丰富训练数据上下文信息,提升训练数据多样性。使用该策略,识别模型的准确率进一步提升到76.3%(+0.5%)。
4.TextRotNet:自监督的预训练模型
TextRotNet是使用大量无标注的文本行数据,通过自监督方式训练的预训练模型。该模型可以初始化SVTR_LCNet的初始权重,从而帮助文本识别模型收敛到更佳位置。使用该策略,识别模型的准确率进一步提升到76.9%(+0.6%)。
5.联合互学习策略
UDML(Unified-Deep Mutual Learning)联合互学习是PP-OCRv2中就采用的对于文本识别非常有效的提升模型效果的策略。在PP-OCRv3中,针对两个不同的SVTR_LCNet和Attention结构,对他们之间的PP-LCNet的特征图、SVTR模块的输出和Attention模块的输出同时进行监督训练。使用该策略,识别模型的准确率进一步提升到78.4%(+1.5%)。
6.无标注数据挖掘方案
UIM(Unlabeled Images Mining)是一种非常简单的无标注数据挖掘方案。核心思想是利用高精度的文本识别大模型对无标注数据进行预测,获取伪标签,并且选择预测置信度高的样本作为训练数据,用于训练小模型。使用该策略,识别模型的准确率进一步提升到79.4%(+1%)。
三、整体效果指标对比
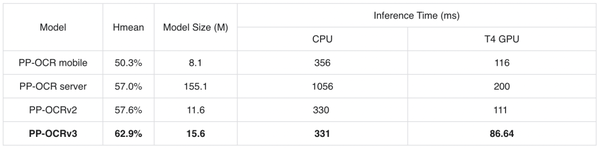
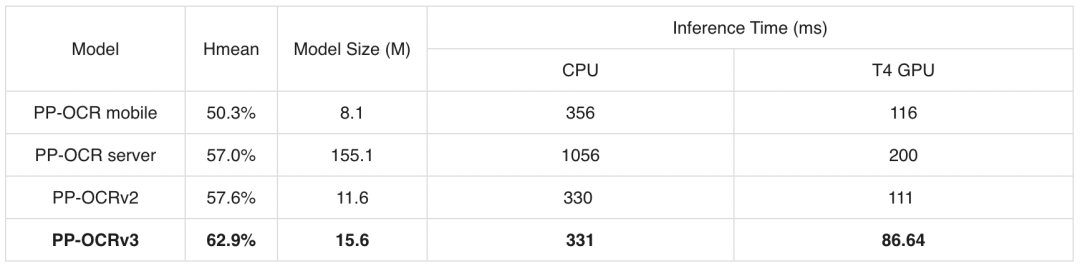
经过上述文本检测和文本识别9个方面的优化,最终PP-OCRv3在速度可比情况下,在中文场景端到端Hmean指标相比于PP-OCRv2提升5%,效果大幅提升。具体指标如下表所示:
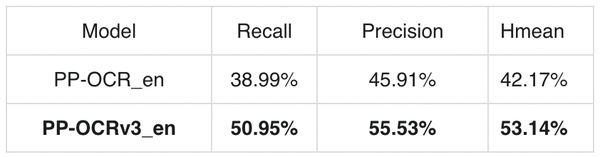
在英文数字场景,基于PP-OCRv3单独训练的英文数字模型,相比于PP-OCRv2的英文数字模型提升11%,如下表所示。
在多语言场景,基于PP-OCRv3训练的模型,在有评估集的四种语系,相比于PP-OCRv2,识别准确率平均提升5%以上,如下表所示。同时,PaddleOCR团队基于PP-OCRv3更新了已支持的80余种语言识别模型。


大家如果觉得不错,建议访问GitHub点个star关注收藏哈。
https://github.com/PaddlePaddle/PaddleOCR



