
GAE

1. GAE的动机
本文假设大家知道概率论中的随机变量与期望(知道怎么用样本求期望就行)的概念,以及强化学习的概念(s, a, r, s' )【觉得公式会推导的话,直接看1.1 GAE作用就行了】
1.1 先看一下GAE的表达式


红框里的表达式有很多种!最初的由来是一个策略的价值函数,当我们估计一个策略的价值函数时,有很多种方法,主要有两大类:基于蒙特卡洛估计(MC)的;基于时间差分(TD)的。这两种方式都存在着各自的优点与缺点。基于MC的没有偏差,而方差大;基于TD的偏差大,方差小。我们想鱼和熊掌兼得(当然不可能了,但是我们希望尽量能兼得),所GAE通过引入一个是用来平衡偏差与方差的。它是如何做的呢?很正常想到的办法是用一部分的MC用一部分的TD,这样就需要对MC和TD分别加权,所以GAE就是通过引入对这两部分加权。
- MC、TD是用来干啥的?
- 用来估计值函数的(强化学习中的值函数有两个:状态价值函数V,动作价值函数Q)
- MC需要等到一个状态和所有的反馈都知道,把这个return坐位值函数的目标
- TD只需要等待下一步完成更新
- 为啥MC无偏方差大?为啥TD有偏方差小?
- MC无偏方差大:对应3.2.1
- T D有偏方差小:对应3.2.3
- 最后的GAE的公式是怎样推导出来的?
- 对应3.3
2. Q函数的由来为啥使用它们?
2.1 首先强化学习目标是啥?
答:最大化累积折扣奖励,累加奖励是(大写的代表的是随机变量,小写的是样本),:


我们知道这个折扣奖励值,是由智能体经过采样一系列轨迹得到的,既然采样了,就涉及到期望的概念了,我们希望通过足够的样本去估计总体的概率分布,就用期望值量化。所以把上述公式用样本表达出来:


U_t 的随机性来源来自哪里呢?奖励 R_{t+1} 依赖于状态 S_t (已观测到)与动作 A_t (未知变量),奖励 R_{t+2} 依赖于 和(未知变量),奖励 R_{t+2} 依赖于 S_{t+2} 和 A_{t+2} (未知变量),以此类推。所以 U_{t} 的随机性来自于这些动作和状态:
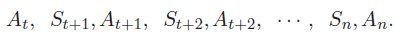
动作的随机性来自策略函数,状态的随机性来自状态转移函数。
2.2 我们用什么表达累积折扣奖励函数呢?
答:期望的形式,这里有两种表达方式
这两种表达方式都能表达奖励的期望,只是出发的角度不同(一定要注意牢记这个,不能混淆)
- 动作价值函数Q
- 状态价值函数V


上式的意思是通过E右下角的所有随机变量对U求期望(类比大学的概率E(x),x是随机变量)
但是我们想消去动作的随机性,动作价值函数只和状态 s_t 有关,所以把动作价值函数表示成了状态价值函数:
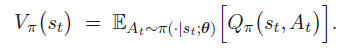
期望不太好求,我们希望使用样本来求期望,这里的蒙特卡洛(MC)其实使用样本来求期望(想想离散变量如何求期望?)
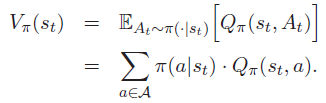
2.3 策略梯度的目标函数
当我们使用神经网络(参数 \theta 代表神经网络的参数)近似智能体的策略时,状态价值函数能表达成如下:

如果一个策略越好,神经网络参数越好,V的值越大,那么对于状态S,V的均值也应该很大
所以,策略梯度的目标函数为:

经过一番公式推导如下:
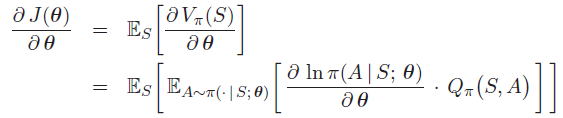



这里 Q_{\pi}(S,A) 以及 ln\pi(A|S;\theta) 是不知道的,所以我们可以通过采集样本来求得上面的策略梯度,用g来表示(也就是采集样本(s, a, r, s'),求期望):

这里为什么我没有对 Q_{\pi}(S,A) 进行展开呢?因为可以 Q_{\pi}(S,A) 被很多不同公式的替换,GAE也是在这里进行操作!
3 重点来了!GAE解决MC和TD的问题
这里我们使用将进行展开, Q_{\pi}(S,A) 可以被很多公式替换,如GAE论文中:


3.1 MC估计
再强调一下,MC是类似概率论中的随机采集样本,来求得这一批样本的期望(自己理解的,可能不对)
首先看一下原始策略梯度函数
使用MC如何估计 Q_{\pi}(S,A) 呢?2.2中说了,累积折扣奖励的期望可以被Q和V表示,所以Q可以通过 u_t 观测到,想想一局游戏或模拟的折扣回报是什么?

累积折扣奖励可以被动作价值函数Q表示:

使用观测到的 u_t 求策略梯度,如下:

3.1.2 MC无偏方差大
但是这个MC有个特点:无偏,有方差,我用手画了一下MC估计为啥是无偏(字太难看了,还有懒,打不动字),如下:


那它的方差怎么看?
- 我们观测到当前的,但是后面的 R_{k} 从t时刻到n时刻都是随机变量,随机变量维度高,所以方差高(自行百度为啥随机变量维度高,方差大)
其实上述方法就称作REINFORCE,对应GAE论文中的第2个:


带基线的REINFORCE


上面的办法不好,在这里我们把近似的 Q_{\pi}(s,a) 稍微变换一下,性能就能得到大幅度的提升。把 Q_{\pi}(s,a) 减去一个b(只要这个b与依赖动作就可以,这样求梯度之后带b的一项相当于常数,不影响策略梯度目标函数)
3.2 TD估计 Q_{\pi}(s,a)
3.2.1 通过神经网络来近似
我们使用另一种方法近似 Q_{\pi}(s,a) ,神经网络通过学习,根据贝尔曼方程可以知道:


这里继续采样,想计算这个期望,得到一系列观测:

这个y代表的是神经网络中所谓的“标签”。
对应GAE论文中:


3.2.2 优势函数估计 Q_{\pi}(s,a)
我们还是想像3.1中减去一个值,使它的估计更准确:




3.2.3 TD估计 Q_{\pi}(s,a) -有偏差方差小
当使用一个b作为基线的时候,我们令b=V(状态价值函数V和动作a无关),再根据贝尔曼方程得:


从轨迹中抽样得:
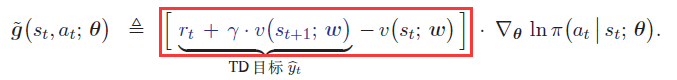

红框里就是TD- \delta , 因为这里的值函数都是由神经网络近似来的,不完全等于真正的累积折扣奖励的值,所以有偏差,为什么说它的方差小?因为贝尔曼方程,这里的随机变量少,所以方差较低。
3.3 GAE
现在我们把所有能估计的表达式用 A^{n}_t 来表示:

把\delta带入:


当将每一个估计值函数展开时:


最后有:

现在到了我们开头说的,它是如何平衡偏差与方差的?将 A^{k}_t 乘以(1-\lambda)展开,当 \lambda 为0时,他就是TD- \delta 的表达式;当 \lambda 为1时:就是MC的表达式,不为0、1就是在权衡:
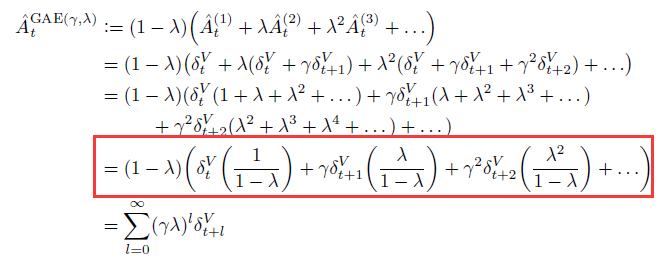

红框最后如何推导成最后的表达形式?--- 等比数列求和
最后主要参考王树森老师的课程!以及知乎各大网友的博客,以后如果有时间,把所有公式统一到一起吧,因为结合了王老师的课程与GAE的论文,个别公式不统一,其实只是符号表达不同,仔细琢磨一下,应该能看懂!这个写了一天。。。第一次 写的不是很好,请大家谅解~