![[细读经典]fastpitch - 带音高预测的并行tts](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[细读经典]fastpitch - 带音高预测的并行tts

前言/简介
这个也是2021年10月挖的坑。今天正好是日本放假(成人节),有点可以发呆的时间,正好填坑了。
小二,上酒~~
arxiv上显示的时间是2021年2月份的。


我司nvidia的大神的作品。一共只有五页,用的是icassp的模板。
摘要
我们提出了 FastPitch,一个基于 FastSpeech 的完全并行的文本到语音模型,以基频轮廓(fundamental frequency contours)为(输出)条件。 该模型在推理过程中预测音高轮廓(pitch contours)。
通过改变这些(对pitch的)预测,生成的语音可以更具表现力,更好地匹配话语的语义,最终更能吸引听众。
使用 FastPitch 均匀地增加或降低音高,从而可以产生类似于语音的随意调制(voluntary modulation)的语音。 对频率轮廓的调节(frequency contours)提高了合成语音的整体质量,使其与最先进的技术相媲美。
它不会引入额外的开销,FastPitch 保留了有利的、完全并行的 Transformer 架构,具有超过 900倍 的实时因子用于典型语音的 mel-spectrogram(梅尔谱的) 合成。
这个简介写的吧。。。太绕了。。。上面的粗体的文字,都是不怎么明白的。。。继续往下看吧。
模型描述
模型架构解析
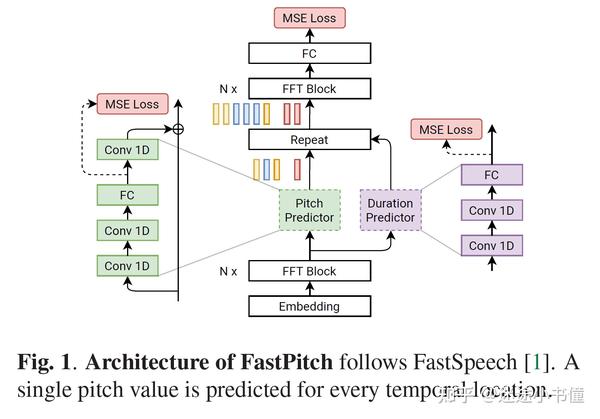

通过上图,详细展开一下fastpitch的细节。
参照fastspeech,fastpitch里面主要也是两个feed-forward transformer(FFTr)模块:
- 第一个是负责输入文本tokens的”编码“;
- 第二个是负责输出frames。
论文中两次用到了所谓”in the resolution of“,是”解决“的意思吗?单独看resolution,是”分辨率“。。。不搭啊。。。
出场人物:
x=(x1, x2, ..., xn)是n个(注意,n,这是输入的序列的长度!)输入词汇单元(lexical units)的序列;
y=(y1, y2, ..., yt)是目标梅尔刻度谱(梅尔谱?mel-scale spectrogram)frames,
那么,第一个FFTr模块是产出x的隐变量表示:
h=FFTr(x)
然后,这个隐变量表示(张量)h,被用来预测每个character(嗯?怎么不是lexical units了?)的时长(duration;上图中部右边的紫色的部分)和平均音高(average pitch;上图中左部的绿色部分)。两个预测
