![[NAACL2021]A Frustratingly Easy Approach for Joint Entity and Relation Extraction](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[NAACL2021]A Frustratingly Easy Approach for Joint Entity and Relation Extraction

论文题目: A Frustratingly Easy Approach for Joint Entity and Relation Extraction
论文地址: https://aclanthology.org/2021.naacl-main.5.pdf
论文代码: https://github.com/princeton-nlp/PURE
目前关于两个子任务联合的工作大概有(1) 联合解码(structured prediction)
(2) 共享参数(multi-task learning)
在NLP研究人员的印象中, joint 的方法一般优于pipline的方法, 今天的这篇paper就打破了人们一贯的印象, 在多个数据集上证明了pipline 的方式效果好与joint方法, pipline的做法是首先识别句子中所有是的实体, 然后遍历每个实体对, 判断每个实体对之间的关系类型(包括无关系)
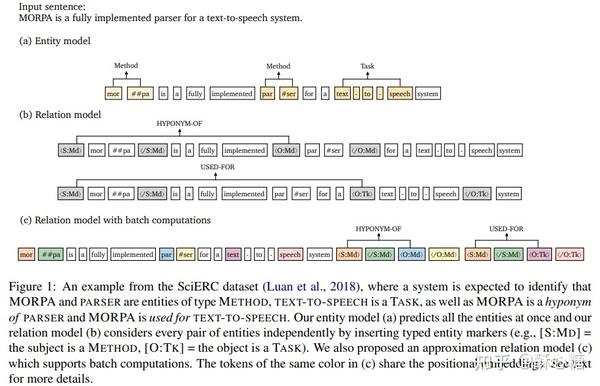

实体识别: 本文采用了standard span-based model, 在此不过多描述, 在之前的针对span-based识别实体的一篇论文中给出过详述, https://zhuanlan.zhihu.com/p/336927442, 本博文的重点放在了关系抽取上面
关系抽取: 在判断关系方面, 本文没有采用复杂的依存关系树等语义结构, 也没有使用大热的GCN模型, 简单地在两个实体的前后各插入了开始和结束标签, 仅用两个实体前面的标签就能获得非常好的效果. 也说明了实体的类型对于两个实体之间的关系判断很重要
关于标签: 为了区分两个实体, 一个实体的标签是以<S 开头, 另一个实体以<O为标示, 因为两个实体的类型对于判断二者之间的关系有很大的帮助, 所以将两个实体的类型也作为标签的一部分. 以paper中给出的example讲述:


在句子 MORPA is fully implemented parser for a text-to-speech system. 中 MORPA 和 parser是两个实体, 并且两个实体的类型都是Md, 所以设计出的两对标签分别是<S:Md> </S:Md> 和 <O:Md> </O:Md> , 实体可能是多个token组成, 加前后标签的目的其实是给出了实体的范围. 经过模型的fine-tune 训练后, <S:Md> 的embedding 代表实体MORPA, 而<O:Md>的embedding 则表示另一个实体parser. 将<S:Md> 和 <O:Md>两个变量串接后进行softmax即可得到两个实体的关系类型
如果模型中应用了bert, 为了防止设计的标签被BertTokenizer 切片, 需要将这些涉及的标签添加到bert 的词典中, 具体如下
from transformers import BertTokenizer, BertModel
bert_tokenizer = BertTokenizer.from_pretrained('dataset/scibert_scivocab_cased/')
bert_model = BertModel.from_pretrained('dataset/scibert_scivocab_cased/')
ADDITIONAL_SPECIAL_TOKENS = ["<S:Md>", "</S:Md>", "<O:Md>", "</O:Md>"]
bert_tokenizer.add_special_tokens({"additional_special_tokens": ADDITIONAL_SPECIAL_TOKENS})
bert_model.resize_token_embeddings(len(bert_tokenizer))另外在关系判断中, 本文还使用了Cross-sentence text 特征, 将本句子的前后句文本也作为特征用进了模型, 具体的做法是: 在前一句和后一句中分别截出 (W - n)/2个文本拼接到本句的前后以丰富文本的信息, 其中 n 是本句的长度, W 是采用的固定值100.
batch计算的技巧:
如果句子中有多个实体对需要判断关系, 如果处理?


句子有三个实体: 实体1 morpa, 实体2 parser, 实体3 text-to-speech, 要判断实体1和实体2的关系, 实体1和实体3的关系, 为了一次性判断两个实体对之间的关系, 没有在句中的三个实体的前后插入开始和结束标签, 而是统一放在句末, 标签的顺序是:
<S:Md></S:Md><O:Md></O:Md> <S:Md></S:Md><O:Tk></O:Tk>
值得注意的是: 实体1 参与了两次的关系判断,分别与实体2 和实体3, 在实体1的标签出现了两次
那么现在问题是: <S:Md> 和</S:Md> 是如何标记实体1在句中的位置的以及实体的长度??
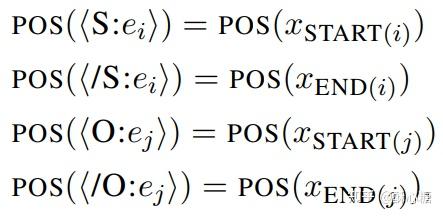

本文中定义了标签的位置向量, 并且进一步定义了句子中各部分在transformer中参与attention.


假设batch = 3 , 即一次性处理三个句子, 三个句子需要pad 补齐. 在代码中处理是:
根据上图中每部分的attention, 在bert中的处理方式如下:
目前我们应用bert最多的就是给出word_ids, 得到bert输出的句子中的每个token的向量,如下所示:
last_hidden_states = bert_model(word_ids)[0] # Models outputs are now tuples但在本文中涉及了positionids 和 mask_ids,
类BertModel的forward函数中, 有两个参数position_ids 和 attention_mask
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):在源码中 position_ids的设计是:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device)词序列的位置从0开始, 遇到实体的标签则更改成实体的位置即可(开始标签的位置是实体的第一个词的位置, 结束标签的位置是实体最后一个词的位置)
mask_ids 的设计是:


last_hidden_states = bert_model(word_ids, attention_mask, position_ids)[0]因为原论文没有给出源码, 这些都是自己的想法, 假设batch = 2, 两个句子中需要判断关系的实体对个数不一致, 无需将句子对个数补齐, 下图是关于两个句子的attentionmask的设计, 再传入bert_model之前, 需要将两个attention_mask在0维上串接, (其他同学有不同意见,请留言)


关于为什么pipline不如Joint的好, 这些问题可以在参考文献中别的大牛对于该篇文章的解读
每次看源码总是有收获, 以后要经常多看多想多思:
(1) 首先是包 allennlp, 在今年过年的时候大概想要实现的功能就是batch_index_select, 费劲周折才有所得, 结果, 在allennlp中已经实现啦, 看来要好好研究下, 看看都实现了哪些功能, 这样下次用起来就方便多了
from allennlp.nn.util import batched_index_selecthttps://allennlp.org/tutorials
quick start : https://guide.allennlp.org/your-first-model
源码: https://codechina.csdn.net/mirrors/allenai/allennlp?utm_source=csdn_github_accelerator
https://arxiv.org/pdf/1803.07640.pdf
学习AllenNLP专栏: https://zhuanlan.zhihu.com/p/102324519
(2) 竟然没发现tensor 也可以zip
## sequence_ouput 的shape[batch, seq_length, 768],
## sub_idx 的shape是[batch, 1], 最后在0维上进行拼接(即batch), zip也是在batch上遍历
sub_output = torch.cat([a[i].unsqueeze(0) for a, i in zip(sequence_output, sub_idx)])
obj_output = torch.cat([a[i].unsqueeze(0) for a, i in zip(sequence_output, obj_idx)])参考文献:
