如何理解链接预测(link prediction)?

泻药。
人们永远生活在无知的洞穴中,所见的实际是对象的影子,而不是其本身。—— 柏拉图
总的来说,Link Prediction 是一个 Graph 问题,它的目标是根据已知的节点和边,得到新的边(的权值/特征)。但是,就像楼上两个同学解释的一样,Link Prediction 的外延广泛,横看成岭侧成峰,因此同学们对它的理解也千差万别。
在不同的 task 中,Link Prediction 被用于:
- 在社交网络中,进行用户/商品推荐
2. 在生物学领域,进行相互作用发现
3. 在知识图谱中,进行实体关系学习
4. 在基础研究中,进行图结构捕捉
在不同的 work 中,Link Prediction 还会被称为(可以使用这些关键词检索哦):
- Edge Embedding/Classification
2. Relational Inference/Reasoning
3. Graph Generation(一种是从节点生成边,另一种是从噪声生成图,前者是 Link Prediction)
最近 Graph Convolution 比较火,这里推荐几个基于 Graph Convolution 的 Link Prediction。下文中的代码实现大部分来自 pytorch_geomatric,实现优雅,值得一看~
GAE
使用自动编码器进行 Link Prediction 是 kipf 两三年前的工作,模型简洁,效果也还不错。模型包括编码器和解码器两部分。


编码器
Graph 上的编码器使用的是 GCN,即:
Z=GCN(X,A)
GCN 主要做了两件事(如果不了解详情,请点击这里):
1. 抓住决定实体关系的主要特征,剔除冗余特征,获得推理能力
如果在好友推荐任务中,我们可以这样理解:决定好友关系的特征有很多,比如性别、受教育水平、爱好、星座、颜值、装逼水平等等。但是在实际社交网络中,我们会发现只有极少数星座狂热分子会根据星座决定自己的好友关系。在剔除这些扰动后,我们可能会得到一个复杂的规律,比如两个喜欢追番的男研究生一定会成为朋友。
2. 将节点特征与周围节点特征融合
如果在好友推荐任务中,我们可以这样理解:好友关系的建立不仅与一个人的自身特点有关,还和他的交友偏好有关。比如肥宅更喜欢关注美女,他的朋友都是美女。我们就不能因为他是男性而给他推荐其他男性。
GAE 的编码的处理过程如下:
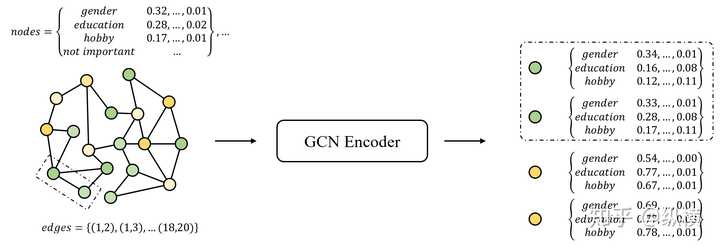

单层的 GCN 一般效果较差,因此我们通常采用多层 GCN:
class EncoderGCN(nn.Module):
def __init__(self, n_total_features, n_latent, p_drop=0.):
super(EncoderGCN, self).__init__()
self.n_total_features = n_total_features
self.conv1 = GCNConv(self.n_total_features, 11)
self.act1=nn.Sequential(nn.ReLU(),
nn.Dropout(p_drop))
self.conv2 = GCNConv(11, 11)
self.act2 = nn.Sequential(nn.ReLU(),
nn.Dropout(p_drop))
self.conv3 = GCNConv(11, n_latent)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.act1(self.conv1(x, edge_index))
x = self.act2(self.conv2(x, edge_index))
x = self.conv3(x, edge_index)
return x解码器
在很多任务中,编码器和解码器使用对偶结构。在 Link Prediction 任务中不是如此,而更像一个分段任务:编码器完成了对节点的编码工作,而解码器需根据节点解码生成边。根据节点特征计,计算边的方法有很多。GAE 使用的是节点特征的点积 + 激活函数,即:
\hat{A}=\sigma(Z^TZ)\\
这种方法在计算上比较简洁,可以被理解为两个节点的独立事件概率相乘。
如果在好友推荐任务中,我们可以这样理解:肥宅很想和一位美女交朋友,他与女性的交友意愿(概率)为 0.98,但是这位美女很讨厌肥宅,认为男人都是大猪蹄子,她与男性的交友意愿(概率)为 0.01,那么最终他们的交友概率就会变为 0.09(残忍的舍入了)。
GAE 的解码器的处理过程如下:
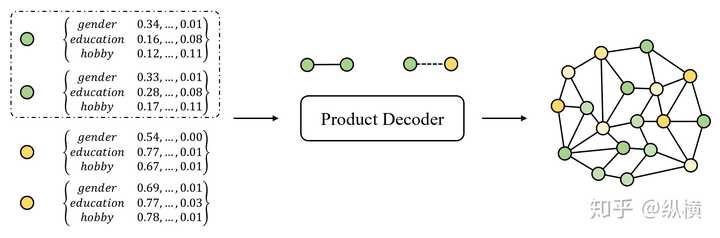

实现起来比较简单:
class DecoderGCN(nn.Module):
def __init__(self):
super(DecoderGCN, self).__init__()
def forward(self, z):
A = torch.mm(z, torch.t(z))
A = torch.sigmoid(A)
return A损失函数
可以看到,在整个过程中,有训练参数的只有编码器。要优化这些训练参数,需要一个损失函数计算 A 和 \hat{A} 的相似度(即每条边存在的概率分布与 ground truth 的差距)。这里直接使用交叉熵就好了。
GVAE
上面的 GAE 用于重建(数据压缩和还原)效果还不错,但是如果用于生成就有点捉襟见肘了。要模型计算多样化的 \hat{A} ,就需要我们提供多样化的 Z 。而 Z 又是由输入数据计算而来的,在拿到目标 Graph 之前,只有上帝才知道要提供什么样的 Z 。
那么有没有办法让模型根据已知的 Z 进行微调呢?VAE 已经替我们解决了这个问题。
编码器:
为了进行微调,在生成 Z 的过程中,我们不直接通过映射得到 Z ,而是先计算 Z 在每个维度上的所有取值的概率(分布)。在得到概率分布后,我们只需要根据概率分布,产生一组随机变量就可以得到微调后的 Z 了。为了便于计算,我们将这个分布约束为高斯分布(只需要确定平均值和标准差就可以确定分布表达式啦)。
GVAE 的编码器处理过程如下:


在好友推荐任务中,我们可以这么理解:有一个肥宅,他是游戏宅的可能性为 0.4-0.5,他是动漫宅的可能性是 0.5-0.6。如果不进行随机采样,他很有可能一直被认定为动漫宅,因而没办法认识新的游戏宅朋友。而进行随机采样的话,他还是很有可能会被认定为游戏宅,从而被推荐游戏宅朋友的。
具体来说,我们把编码器的输出改成了 Z 在每个维度上的(概率分布的)平均值和标准差。我们将使标准差与 noise (随机生成的变量)相乘,再与平均值相加,得到高斯分布上采样到的一个 Z :
u=GCN_u(X,A)\\ \sigma=GCN_{\sigma}(X,A)\\ z=u+\epsilon \times \sigma
实现起来也比较简单:
class EncoderGCN(nn.Module):
def __init__(self, n_total_features, n_latent, p_drop=0.):
super(EncoderGCN, self).__init__()
self.n_total_features = n_total_features
self.conv1 = GCNConv(self.n_total_features, 11)
self.act1=nn.Sequential(nn.ReLU(),
nn.Dropout(p_drop))
self.conv2 = GCNConv(11, 11)
self.act2 = nn.Sequential(nn.ReLU(),
nn.Dropout(p_drop))
self.conv3 = GCNConv(11, n_latent)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.act1(self.conv1(x, edge_index))
x = self.act2(self.conv2(x, edge_index))
x = self.conv3(x, edge_index)
return x
def reparametrize(self, mean, log_std):
if self.training:
return mean + torch.randn_like(log_std) * torch.exp(log_std)
else:
return mean
def encode(self, *args, **kwargs):
r""""""
self.mean, self.log_std = self.encoder(*args, **kwargs)
z = self.reparametrize(self.mean, self.log_std)
return z解码器
我们仍然沿用 GAE 的做法。
损失函数
在上文中,我们假设 Z 的概率分布为高斯分布。因此,在损失函数中我们还需要添加这个约束,在训练参数的优化过程中,使 Z 的分布逼近高斯分布。要达到这个目标,我们只需要最小化 Z 的分布与高斯分布之间的差异,即优化 KL 散度即可:
loss=Cross\ Entropy-KL(p(Z|A,X)||\prod{N(z_i|0,I)})\\
到此为止,Graph Auto-encoder 已经进化成了 Graph Variational Auto-encoder。可喜可贺可喜可贺~
上述两个模型的代码可以看这里。
ARGA
在 GVAE 的设计中,一个很关键的问题是:模型的编码器是否真的能够习得一个高斯分布。如果不能,我们按照高斯分布的采样毫无意义。
有没有办法让编码器显式地逼近高斯分布呢?AAE 已经替我们解决了这个问题。我们将 GAN 网络与 AutoEncoder 相结合,把模型分为生成器和检测器两部分。
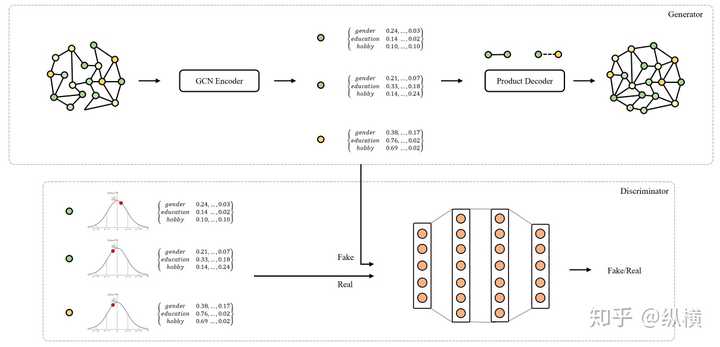

生成器
生成器部分我们直接使用上文中介绍过的 GAE。通过编码器得到 Z ,再通过解码器生成 Graph。
class EncoderGCN(nn.Module):
def __init__(self, n_total_features, n_latent, p_drop=0.):
super(EncoderGCN, self).__init__()
self.n_total_features = n_total_features
self.conv1 = GCNConv(self.n_total_features, 11)
self.act1=nn.Sequential(nn.ReLU(),
nn.Dropout(p_drop))
self.conv2 = GCNConv(11, 11)
self.act2 = nn.Sequential(nn.ReLU(),
nn.Dropout(p_drop))
self.conv3 = GCNConv(11, n_latent)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.act1(self.conv1(x, edge_index))
x = self.act2(self.conv2(x, edge_index))
x = self.conv3(x, edge_index)
return x
class DecoderGCN(nn.Module):
def __init__(self):
super(DecoderGCN, self).__init__()
def forward(self, z):
A = torch.mm(z, torch.t(z))
A = torch.sigmoid(A)
return A检测器
检测器中,我们需要产生一个真实的高斯分布,并进行抽样得到真实样本。接着,将抽样得到的正(+)样本和生成的负(-)样本 Z 放入多层感知器进行区分。这样,『 Z 的分布与高斯分布之间的差异』就可以用『Z 与 + 样本的差异』来替换了。
class Discriminator(nn.Module):
def __init__(self, n_input):
super(Discriminator, self).__init__()
self.fcs = nn.Sequential(nn.Linear(n_input,40),
nn.ReLU(),
nn.Linear(40,30),
nn.ReLU(),
nn.Linear(30,1),
nn.Sigmoid())
def forward(self, z):
return self.fcs(z)
class ARGA(nn.Module):
def __init__(self, n_total_features, n_latent):
super(ARGA, self).__init__()
self.encoder = EncoderGCN(n_total_features, n_latent)
self.decoder = DecoderGCN()
self.discriminator = Discriminator(n_latent)
def forward(self, x):
z_fake = self.encoder(x)
z_real=torch.randn(z_fake.size())
A = self.decoder(z_fake)
d_real=self.discriminator(z_real)
d_fake=self.discriminator(z_fake)
return A, d_real, d_fake
def simulate(self, x):
z_fake = self.encoder(x)
A = self.decoder(z_fake)
return A损失函数
在生成器中,我们需要区分真实的邻接矩阵A 和生成的邻接矩阵 \hat{A} :
A_loss = nn.BCELoss(reduction='sum', weight=torch.tensor(weights, dtype=torch.float))(A_new, A_orig)在检测器中,我们需要区分从高斯分布抽样得到的样本(real)和 Z (fake):
d_loss_real = nn.BCELoss(reduction='mean')(real, torch.ones(real.size()))
d_loss_fake = nn.BCELoss(reduction='mean')(fake, torch.zeros(fake.size()))到此为止,Graph Variational Auto-encoder 已经进化成了 ARGA。可喜可贺可喜可贺~
推荐阅读
还有很多同样出色的工作,不方便一一列举,这里还是给新入坑的同学推荐几篇 Survey 吧:
A Survey of Link Prediction in Complex Networks
Link prediction in complex networks: A survey
A Comprehensive Survey of Graph Embedding(Edge embedding part)
Network Structure Inference, A Survey: Motivations, Methods, and Applications