requests:r.encoding比r.apparent_encoding更准确?


综合两位的答案,我又找到了相关源码来看,现在有更深的理解,总结如下:
1、总体
encoding和apparent_encoding本来都是Request类的方法,经过@property 装饰之后,可以像属性那样调用,即r.encoding和r.apparent_encoding
选择顺序上,优选r.encoding,如果r.encoding不存在再去找r.apparent_encoding.
2、具体来看r.encoding和r.apparent_encoding的值是怎么来的
(1)先说r.encoding
response.encoding = get_encoding_from_headers(response.headers)
然后这个get_encoding_from_headers()函数的定义在utils模块里,这个函数大致是做了(不限于)取出headers的'content-type'字段,调用cgi.parse_header方法解析成content_type和params
然后我把这段显示地加入我的代码,目的是想看看content_type和params到底是什么
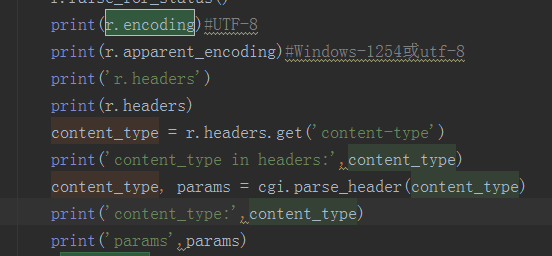

结果:
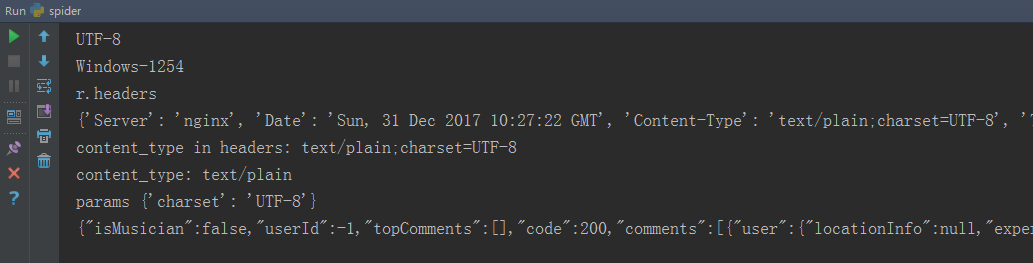

所以,r.encoding确确实实,是从r.headers中content-type字段中的charset的值。在我的例子里,就是utf-8.
(2)再说r.apparent_encoding
chardet.detect(self.content)['encoding']#调用了chardet模块的detect方法,参数给的是r.content
chardet是python的另外一个库,这里就不不深究detect的实现细节了吧,感觉会比较复杂。
但可以知道,r.apparent_encoding是否准确,其实就是看chardet.detect是否准确。
至少在我这个例子里,是不准确的……
我还是忍不住去看了chardet.detect的实现。
detect()方法在chardet文件夹下__init__.py文件中,内容如图:
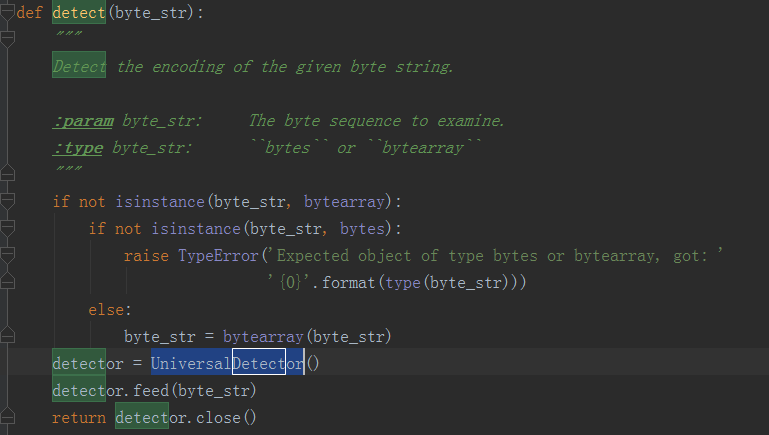

就是首先把输入转换成一个bytearray对象,然后构造一个名叫detector的对象,它是UniversalDetector类的实例。接着调用detector.feed()方法对bytearray对象进行处理。
其中,UniversalDetector的定义和detector.feed()的定义均在这个文件里:
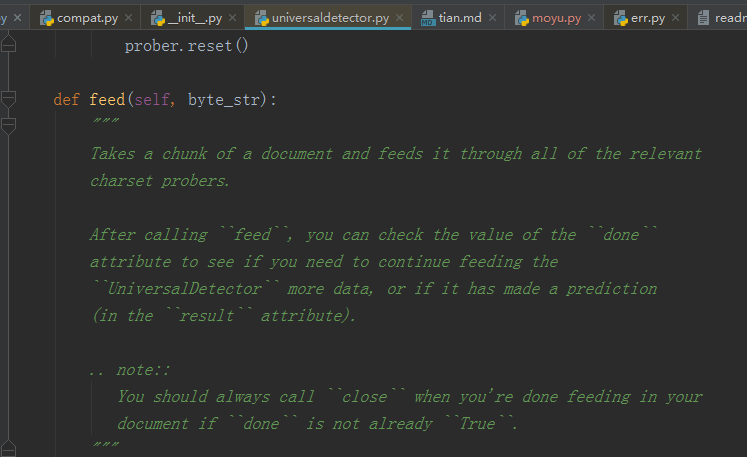

比较重要的是第一段:
Takes a chunk of a document and feeds it through all of the relevant
charset probers.
取出文档的一部分,然后和所有相关的字符集匹配。
# First check for known BOMs, since these are guaranteed to be correct
# If the data starts with BOM, we know it is UTF
首先判断是否是已知的BOM,因为这个是绝对准确的,方法就是startwith检测开头的字段。例如:
if byte_str.startswith(codecs.BOM_UTF8):
# EF BB BF UTF-8 with BOM
self.result = {'encoding': "UTF-8-SIG",
'confidence': 1.0,
'language': ''}# If none of those matched and we've only see ASCII so far, check
# for high bytes and escape sequences
如果上面都不匹配,只有看看会不会是 ASCII,方法是检查high bytes and escape sequences。
如果看到了转义,这么处理……
# If we've seen escape sequences, use the EscCharSetProber, which
# uses a simple state machine to check for known escape sequences in
# HZ and ISO-2022 encodings, since those are the only encodings that
# use such sequences.、
如果看到了high bytes(超过127),就要更精细地拿multi-byte probers 和
single-byte probers 去匹配(因为原始ASCII最多127)……
# If we've seen high bytes (i.e., those with values greater than 127),
# we need to do more complicated checks using all our multi-byte and
# single-byte probers that are left. The single-byte probers
# use character bigram distributions to determine the encoding, whereas
# the multi-byte probers use a combination of character unigram and
# bigram distributions.
(这一长段就真的不看了)
注意到返回结果出了encoding还有个confidence,应该是可信度的意思。如果是已知的BOM(也就是是utf编码),confidence的值是1.0,这是最最确定的情况。后面用high bytes and escape sequences,confidence的值是调用get_confidence()方法取得,估计会低一些。
在我这个例子里,所有网页的真实编码都是utf-8,但是有一些被解析成Windows-1254,应该属于解析很勉强,如果打印confidence的值应该不高。
做完这一切以后,我搜索“charset 编码错误”,想要确一个认。相关结果不多,但下面这个算是印证吧。
ps:不止爬虫,以后有需要的情况可以直接import chardet,用chardet.detect(doc)方法来解析编码方式,不过不要完全相信,最好参考下confidence的值。