







一:从生物角度开始
几乎地球上每一种动物都有其特定的神经系统,都是由简单的神经元组合成神经网络,然后完成其特定的功能。比如,简单的低等动物,就像蚂蚁。可能只有几十万个神经元。但可以完成觅食,战斗,判别气味等等复杂的功能。人类的计算机可以模拟上亿个神经元。在理论上讲,能完成的工作远远不止这些。
二:神经元的结构

这是一个人工神经元的结构,模拟了一个生物意义上的神经元。其中x1,x2,x3.......都表示输入,wk1,wk2,wk3表示的是这个神经元对各个输入的权值。bk代表阈值,然后经过一个激活函数处理。得到了这一个神经元的输出,也就是下一个神经元的输入。大家对比一下下面的大脑神经元图片。发现有多相似点。

学过中学生物的都了解,一个神经元有很多树突,这都是这个神经元的输入信号。有一个轴突,是这个神经元的输出信号。轴突的末端分出很多条触手,分别对应到别的神经元的树突,这样就完成了信号的传播。在神经元中,信号的强弱会受到神经元的处理,对应着人工神经元的激活函数。很多个神经元按照如下方式组合在一起,就模拟人的神经系统,得到了神经网络。一个初级模型。
我们就要介绍网络输出与实际输出如何构建联系。
要构建输入神经元与结果(标签)的联系。需要用到一个数学上的概念:梯度下降以及反向传播。下面我们举一个例子
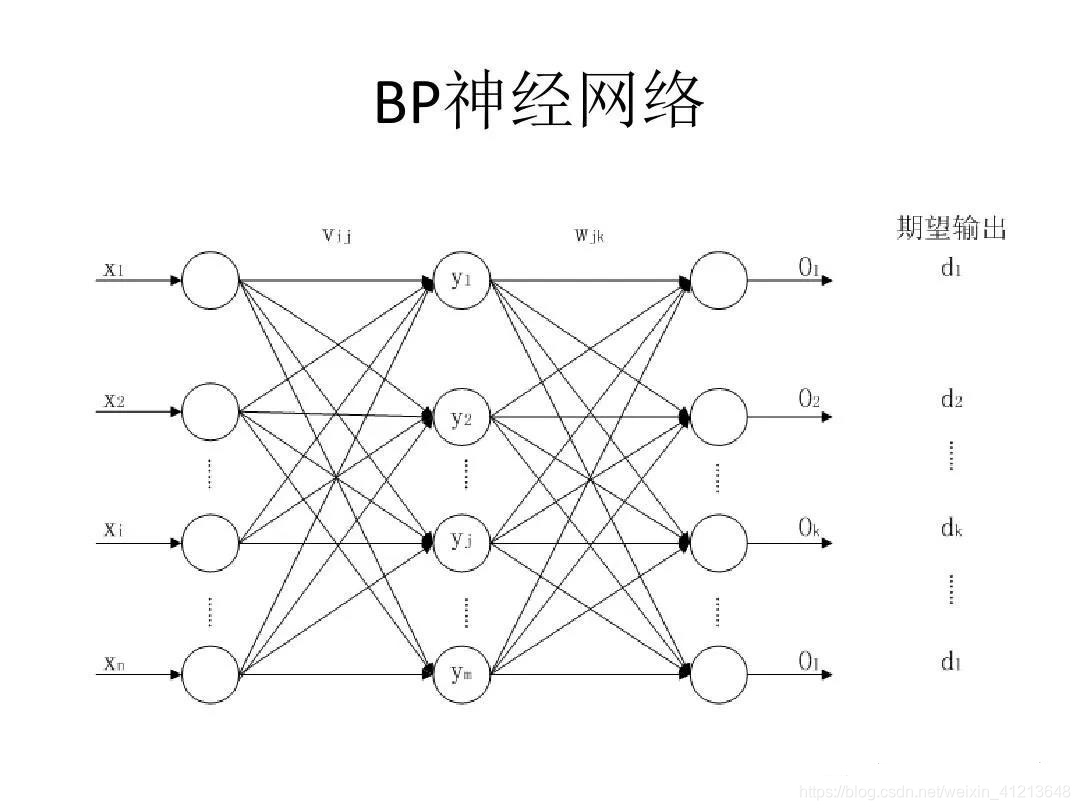
以上神经网络中,x1,x2,x3,x4为输入神经元。每一组输入都对应着一个标签(结果)。神经网络的核心是神经元的权重和阈值。作用是决定每个输入在结果中的重要程度。中间层(隐藏层)越多。拟合的效果越好。但是较少的训练样本对应特别高的拟合程度,会造成比较严重的后果:过拟合,所以不要用过多的隐藏层神经元。
1、反向传播与梯度下降
这是神经网络的核心内容。首先,记住这样一句话:梯度方向是下降速度最快的方向,别问为什么,记住就行了。各位也不要留言问我这个问题,太复杂了,实在不想写。所以,神经网络根据误差调整权值的时候是按照梯度下降的方向调整的。
其次:反向传播实质是误差信息的反向传播。因为只有将误差信息反向传播,才能让前面的神经元知道如何调整自己的权值和阈值。才能优化网络。反向传播也要按照权值来分配误差信息,权值大的神经元调整幅度也大,权值小的神经元调整幅度小,毕竟权值大的应该负主要责任。
2、误差
误差就是你要优化的对象,神经网络的设定是让误差最小。我举一个例子:比如给你一堆自变量x1,x2,x3,x4。一个因变量y1。在训练集中。有一组数据是[2,4,6,7]与12。神经网络输出是11.那么误差就是11-12=-1.误差就是"实际输出-网络输出"。目标函数要让误差最小。才能达到精确预测的目的。
3、链式求导法则
为了让大家更简单的理解神经网络,链式求导的数学原理就不写了。大家也没必要搞得很明白。只需要记住,误差反向传播的过程中,会经过好几层神经元。最后第一层的误差经过权值分配后是倒数第二层的误差。倒数第二层的误差经过下一层权值的分配成为倒数第三层的误差........。依次类推。最后传播到第一层,误差的车轮碾过所有的神经元。改变了所有的权值和阈值,一次训练完成.......。
经过很多次训练以后,权值和阈值都优化到了非常好的地步,就可以进行预测了。
三:神经元的功能
1:输入与输出
对于每一个神经元来讲,输入和输出对于它来讲都十分重要。在这里再引入几个概念概念:
1.1权重w(i,j)。
代表的意思是上一层第i个神经元的输入以多大的比重到达这一层神经网络的第j个神经元.
1.2阈值B。
每个隐藏层神经元都有一个阈值。对应到生物中,意思是信号到了一定的强度才会激发。
1.3激活函数
神经元输入的信号需要经过处理才能够输出,处理输入信号的函数叫做激活函数。常见的激活函数如下

以上函数有共同的特点,将很大范围类的数字集中到很小的区间类,这样能方便进行处理。
四:代码实现
首先我们要定义上面的一些量,这一次我用到的是python作为开发工具。首先定义激活函数,我们用tanh(x)
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)下一步,我们定义这个神经网络。
class NeuralNetwork:
def __init__(self, layers, activation='tanh'):
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append(
(2 * np.random.random((layers[i - 1] + 1, layers[i] + 1)) - 1) * 0.25)
self.weights.append(
(2 * np.random.random((layers[-2] + 1, layers[-1])) - 1) * 0.25)self.weights用来储存这些神经元的权值和阈值。一个for循环,用随机数初始化这些权值。跳出循环后加上阈值。这样就构成了一个神经网络简单模型。
此神经网络的功能是预测。我们还需要定义下面一个功能,由于篇幅有限,关于下面的代码,我在下一篇推送中会详细介绍。
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0] + 1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a下面,我演示一下这个简单的神经网络,我们定义了三层神经网络,实例化的nn就是这样nn = NeuralNetwork([2, 3, 1])。输入层有两个神经元,隐藏层有三个,输出层有一个。这样我们的输入就必须是两个,比如[[0, 0], [0, 1], [1, 0], [1, 1]]。这就是我们用到的输入,一共有四组,每组有两个,输出必须是一个,[0, 1, 1, 0]这是我们用到的四组输出,每组一个,与输入相互对应。这属于训练集。大家有什么不懂的,欢迎留言,我以后详细讲解。
大家记住,这是一个没有经过训练的神经网络,所以网络的输出和实际输出差距很大(网络输出在右下角,实际输出就是定义的四组输出),以后我会讲如何训练神经网络。到时候会达到惊人的吻合。

下面就是全部的代码(一个简单的框架,以后进一步完善)。
import numpy as np
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
class NeuralNetwork:
def __init__(self, layers):
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
for i in range(1, len(layers) - 1):
self.weights.append(
(2 * np.random.random((layers[i - 1] + 1, layers[i] + 1)) - 1) * 0.25)
self.weights.append(
(2 * np.random.random((layers[-2] + 1, layers[-1])) - 1) * 0.25)
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0] + 1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
nn = NeuralNetwork([2, 3, 1])
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
for i in [[0, 0], [0, 1], [1, 0], [1, 1]]:
print(i, nn.predict(i))另外本人还开设了个人公众号:JiandaoStudio ,会在公众号内定期发布行业信息,以及各类免费代码、书籍、大师课程资源。

扫码关注本人微信公众号,有惊喜奥!公众号每天定时发送精致文章!回复关键词可获得海量各类编程开发学习资料!
例如:想获得Python入门至精通学习资料,请回复关键词Python即可。














 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









