






欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章

sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

bootstrapping 解决不知道分布情况下,计算平均值的置信区间


Scikits.bootstrap provides bootstrap confidence interval algorithms for scipy.
At present, it is rather feature-incomplete and in flux. However, the functions that have been written should be relatively stable as far as results.
Much of the code has been written based off the descriptions from Efron and Tibshirani's Introduction to the Bootstrap, and results should match the results obtained from following those explanations. However, the current ABC code is based off of the modified-BSD-licensed R port of the Efron bootstrap code, as I do not believe I currently have a sufficient understanding of the ABC method to write the code independently.
In any case, please contact me (Constantine Evans <cevans@evanslabs.org>) with any questions or suggestions. I'm trying to add documentation, and will be adding tests as well. I'm especially interested, however, in how the API should actually look; please let me know if you think the package should be organized differently.
The package is licensed under the Modified BSD License.
pip install scikits.bootstrap
calc_bootstrap(data)
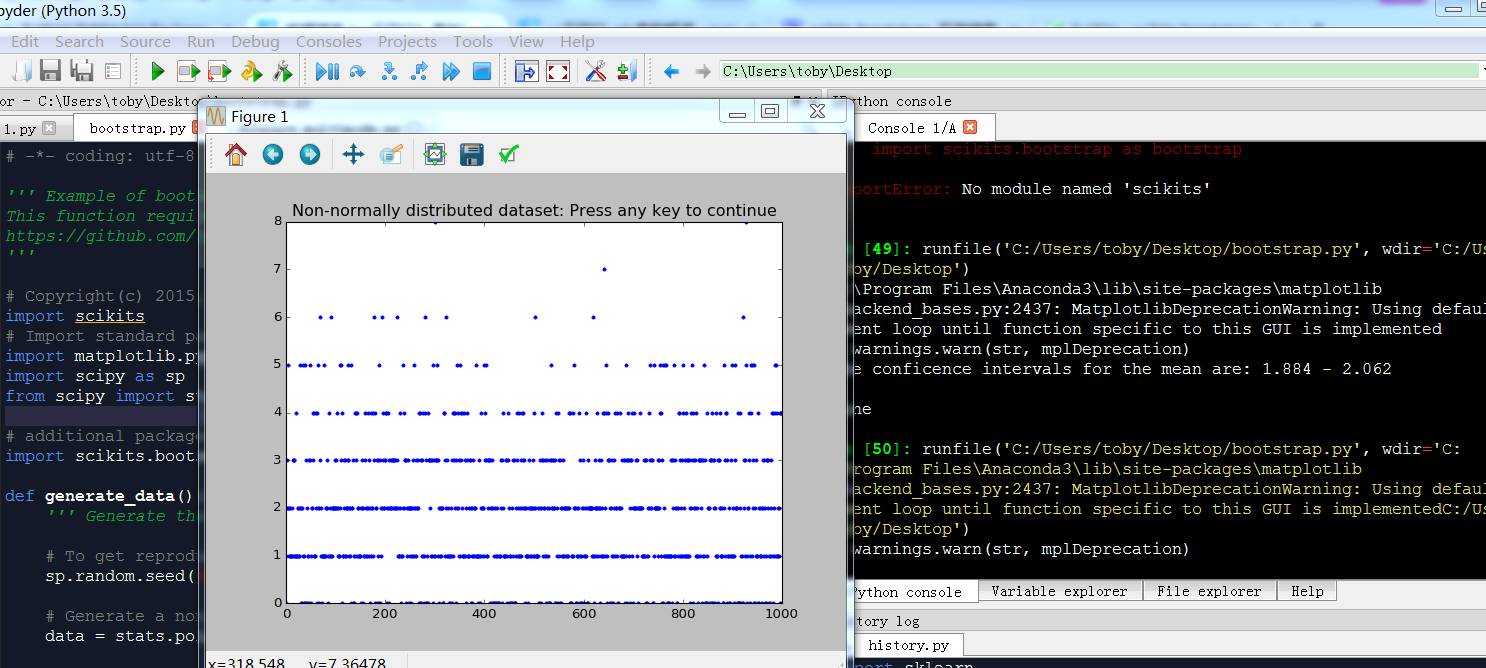
The conficence intervals for the mean are: 4.906 - 5.171
Out[5]: array([ 4.906, 5.171])

bootstrap.py
# -*- coding: utf-8 -*-
''' Example of bootstrapping the confidence interval for the mean of a sample distribution
This function requires "bootstrap.py", which is available from
https://github.com/cgevans/scikits-bootstrap
'''
# Copyright(c) 2015, Thomas Haslwanter. All rights reserved, under the CC BY-SA 4.0 International License
import scikits
# Import standard packages
import matplotlib.pyplot as plt
import scipy as sp
from scipy import stats
# additional packages
import scikits.bootstrap as bootstrap
def generate_data():
''' Generate the data for the bootstrap simulation '''
# To get reproducable values, I provide a seed value
sp.random.seed(987654321)
# Generate a non-normally distributed datasample
data = stats.poisson.rvs(2, size=1000)
# Show the data
plt.plot(data, '.')
plt.title('Non-normally distributed dataset: Press any key to continue')
plt.waitforbuttonpress()
plt.close()
return(data)
def calc_bootstrap(data):
''' Find the confidence interval for the mean of the given data set with bootstrapping. '''
# --- >>> START stats <<< ---
# Calculate the bootstrap
CIs = bootstrap.ci(data=data, statfunction=sp.mean)
# --- >>> STOP stats <<< ---
# Print the data: the "*" turns the array "CIs" into a list
print(('The conficence intervals for the mean are: {0} - {1}'.format(*CIs)))
return CIs
if __name__ == '__main__':
data = generate_data()
calc_bootstrap(data)
input('Done')
一、Introduction
如果说到Bootstrap你会想到什么?是Twitter推出的那个用于前端开发的开源工具包吗?Unfortunately,本文要讨论的并非是Bootstrap工具包,而是统计学习中一种重采样(Resampling)技术。这种看似简单的方法,对后来的很多技术都产生了深远的影响。机器学习中的Bagging,AdaBoost等方法其实都蕴含了Bootstrap的思想。
下面引用的是谢益辉博士关于Bootstrap (和 Jackknife)基本思想的论述,希望能帮助读者对于Bootstrap 建立一个初步的认识:
在统计的世界,我们面临的总是只有样本,Where there is sample, there is uncertainty,正因为不确定性的存在,才使统计能够生生不息。传说统计学家、数学家和物理学家乘坐一列火车上旅行,路上看到草原上有一只黑羊,统计学家说,“基于这个样本来看,这片草原上所有的羊都是黑的”,数学家说,“只有眼前这只羊是黑的”,物理学家则说,“你们都不对,只有羊的这一面是黑的”。这是关于统计和其他学科的一个玩笑话,说明了统计的一些特征,比如基于样本推断总体。
一般情况下,总体永远都无法知道,我们能利用的只有样本,现在的问题是,样本该怎样利用呢?Bootstrap的奥义也就是:既然样本是抽出来的,那我何不从样本中再抽样(Resample)?Jackknife的奥义在于:既然样本是抽出来的,那我在作估计、推断的时候“扔掉”几个样本点看看效果如何?既然人们要质疑估计的稳定性,那么我们就用样本的样本去证明吧。
John Fox的那一系列附录中有一篇叫“Bootstrapping Regression Models”,当我看到第二页用方框框标出那句话时,我才对Bootstrap的思想真正有了了解(之前迷茫了很长时间)。Bootstrap的一般的抽样方式都是“有放回地全抽”(其实样本量也要视情况而定,不一定非要与原样本量相等),意思就是抽取的Bootstrap样本量与原样本相同,只是在抽样方式上采取有放回地抽,这样的抽样可以进行B次,每次都可以求一个相应的统计量/估计量,最后看看这个统计量的稳定性如何(用方差表示)。Jackknife的抽样痕迹不明显,但主旨也是取样本的样本,在作估计推断时,每次先排除一个或者多个样本点,然后用剩下的样本点求一个相应的统计量,最后也可以看统计量的稳定性如何。
在R中简单随机抽样的函数是sample(),其中有个参数replacement表示是否放回,经典的抽样基本都是不放回(replace = FALSE),而Bootstrap则是replace = TRUE;从FALSE到TRUE,小小的一个变化,孕育了Bootstrap的经典思想。
统计推断是从样本推断相应的总体, 有参数法和非参数法。早期的统计推断是以大样本为基础的。自从英国统计学家威廉·戈塞特(Willam Gosset)在1908年发现了t分布后,就开创了小样本的研究。费希尔(Fisher)在1920年提出了似然(likelihood)的概念,一直被认为是高效的统计推断思维方法。半个多世纪以来,这种思维一直占有主导地位,统计学家研究的主流就是如何将这种思维付诸实践,极大似然函数的求解是这一研究的关键问题。
当今计算机技术的高度发展,使统计研究及其应用跃上了一个新台阶。这不仅提高了计算的速度,而且可以把统计学家从求解数学难题中释放出来,并逐渐形成一种面向应用的、基于大量计算的统计思维——模拟抽样统计推断, Bootstrap 法就是其中的一种。
Bootstrap方法最初由美国斯坦福大学统计学教授Efron在1977年提出。作为一种崭新的增广样本统计方法,Bootstrap方法为解决小规模子样试验评估问题提供了很好的思路。当初,Efron教授将他的论文投给了统计学领域的一流刊物《The Annals of Statistics》,但在被该刊接受之前,这篇后来被奉为扛鼎之作的文章曾经被杂志编辑毫不客气地拒绝过,理由是“太简单”。从某种角度来讲,这也是有道理的,Bootstrap的思想的确再简单不过,但后来大量的事实证明,这样一种简单的思想却给很多统计学理论带来了深远的影响,并为一些传统难题提供了有效的解决办法。Bootstrap方法提出之后的10年间,统计学家对它在各个领域的扩展和应用做了大量研究,到了20世纪90年代,这些成果被陆续呈现出来,而且论述更加全面、系统。
很多人会对Bootstrap这个名字感到困惑。英语Bootstrap的意思是靴带,来自短语:“pull oneself up by one′s bootstrap”,18世纪德国文学家拉斯伯(Rudolf Erich Raspe)的小说《巴龙历险记(或译为终极天将)》(Adventures of Baron Munchausen) 记述道:“巴龙掉到湖里沉到湖底,在他绝望的时候,他用自己靴子上的带子把自己拉了上来。”现意指不借助别人的力量,凭自己的努力,终于获得成功。在这里“bootstrap”法是指用原样本自身的数据抽样得出新的样本及统计量,根据其意现在普遍将其译为“自助法”。
二、Explanation
Bootstrap法是以原始数据为基础的模拟抽样统计推断法,可用于研究一组数据的某统计量的分布特征,特别适用于那些难以用常规方法导出对参数的区间估计、假设检验等问题。其基本思想是:在原始数据的范围内作有放回的再抽样, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本。于是可得到参数θ的一个估计值θ^(b),这样重复若干次,记为B 。
设随机样本 X = [x1, x2,...,xn]是独立同分布样本xi~F(x), i = 1, 2,..., n。R(X, F)为某个预先选定的随机变量, 是关于X和F的函数。现要求根据观测样本[x1, x2,...,xn]来估计R(X, F)的分布特征。例如,设θ = θ(F)为总体分布F的某个参数,Fn是观测样本X的经验分布函数(如果你不了解什么是“经验分布函数”可以参考http://blog.csdn.NET/baimafujinji/article/details/51720090), 是θ的估计,记估计误差为
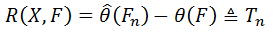
现要由观测样本X =[x1, x2,...,xn]估计R(X, F)的分布特征,Bootstrap方法的实质就是一个再抽样过程,计算R(X, F)分布特征的基本步骤归纳如下:
1)根据观测样本X =[x1, x2,...,xn]构造经验分布函数Fn;
2)从Fn中抽取样本,称其为Bootstrap样本;
3)计算相应的Bootstrap统计量R*(X*,Fn),其表达式为
(2)
式中是Bootstrap样本的经验分布函数;Rn为Tn的Bootstrap统计量;
4)重复过程2)、3)N次,即可获得Bootstrap统计量R*(X*,Fn)的N个可能取值;
5)用R*(X*, Fn)的分布去逼近R(X, F)的分布, 即用Rn的分布去近似Tn的分布,可得到参数θ(F)的N个可能取值,即可统计求出参数θ的分布及其特征值。
由Bootstrap方法的实现步骤可以看出:
1)Rn的统计特性是基于经验分布函数得到的,Tn的统计特性是通过真实分布函数F描述的;
2)Bootstrap方法的一个重要环节就是计算自助统计量Rn的分布;
3)Bootstrap方法的核心思想是利用自助统计量Rn的统计特性来近似Tn的统计特性,因此,Bootstrap方法的效果好坏在很大程度上取决于这二者的近似程度;
4)由式(1)可以看出,Tn的统计特性决定于和θ(F)的统计特性。对于某个具体的分布F而言,θ(F)是一个确定的值,因此,Tn的统计特性取决于
的统计特性;
以Bootstrap方法获取正态分布均值的先验分布为例研究Rn的统计特性。已知观测样本数据 X = [x1, x2, ..., xn], xi~N(μ,σ^2),i = 1, 2, ..., n,则X = [x1, x2, ..., xn]的经验分布(这里考虑参数Bootstrap方法)Fn也是一正态分布
其中,
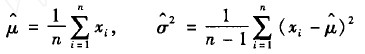
用经验分布Fn的均值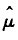
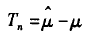
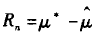
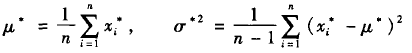
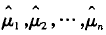
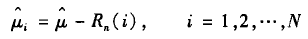
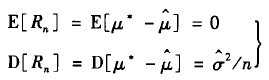
三、Application
文献【5】中给出了22例胎儿受精龄(Y,周)与胎儿外形测量指标:身长(X1,cm),头围(X2,cm),体重(X3,g),数据列于表1。
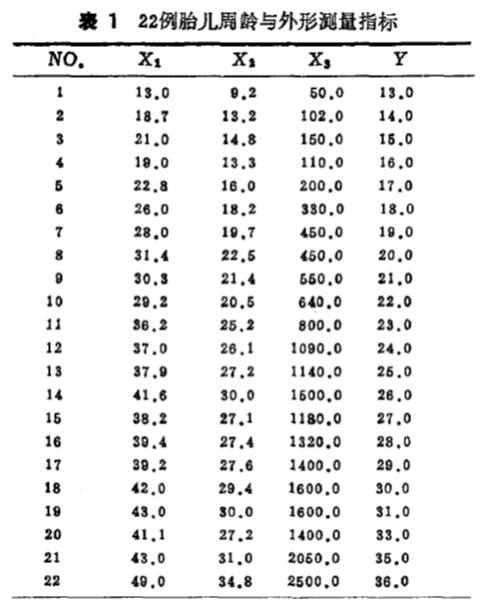
很容易算得三个指标的平均值向量为:X = (33.0455, 23.2636, 936.9091) ---------(2)
协方差矩阵为

对其进行主成分分析,得3个特征根分别为:λ1 = 2.92613, λ2 = 0.07140, λ3 = 0.00247。我们用bootstrap 法来估计第一特征根的标准差及置信区间。
首先在22个个体中作有放回的抽样,每个个体被抽中的概率为1/22,抽样次数仍为n=22,这可以用计算机产生1~22的均匀分布的随机数,相应的编号即为抽中的个体,由这些个体组成的样本就是一个bootstrap样本。如第一
次我们得到22个随机数为:10, 20, 3, 19, 12, 2, 3, 2, 5, 20, 8, 13, 12, 18, 17, 22, 2, 1, 19, 7, 8, 13。由对应的bootstrap 样本求得
如此重复B次(B分别取50, 100, 200, 500, 800, 1000),得
从的频数分布可知,其分布是偏态的。故以上、下2.5%分位数作为其95%置信区间。结果列于附表前半部分。由此得到λ1 的置信区间, 如B = 1000 时, 其95%的置信区间为:2.8919~ 2.9672, 其标准误为0.01946。在整个计算过程中, 只是重复地抽样, 重复地计算λ1, 根据其频数分布的分位数即得到了其置信区间, 无需繁杂的数学推导。事实上,小样本时主成分的置信区间尚无理想的计算方法。

在这里, 来自未知总体F 的原样本被视为经验分布Fe,Bootstrap是在经验分布的基础上作有放回的抽样, 由于Fe 是F 的非参数估计,故由此产生的方法称为非参数的bootstrap , 相应的估计量称为非参数的bootstrap统计量。
事实上, bootstrap亦可以从参数的角度考虑。如上例, X = (X1 , X2 , X3) ,此时设经验分布Fp 是以式(2)为均向量、式(3)为协方差阵的3元正态分布。此时的Bootstrap的样本是从Fp中而不是从Fe (样本)中随机产生,其余步骤相同。由于此时Fp 是F 的一个参数估计,则该法称为参数的bootstrap,相应的估计称为参数的bootstrap估计。结果列于附表后部分。B = 1000时,其95% 的置信区间为: 2. 8431~ 2. 9705,其标准误为0. 03495。
-----------------------------------------------------------------------
本文主要根据以下文献整理而成
[1] 谢益辉,我的一些统计方法观,http://cos.name/2008/11/outlook-on-statistical-methods/,2007-01-27
[2] 谢益辉,朱钰,Bootstrap方法的历史发展和前沿研究,统计与信息论坛,2008年2月,第23卷,第2期
[3] 陈峰,陆守曾,杨珉,Bootstrap估计及其应用,中国卫生统计,1997年,第14卷,第5期
[4] 刘伟,龙琼,陈芳,付敏,Bootstrap方法的几点思考,飞行器测控学报,2007年10月,第26卷,第5期















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









