







暂时跳过Step 3: The Command Line 和Step 4: Working With Data Sources
现在学习Step 5: Statistics And Linear Algebra 部分
Probability And Statistics In Python: Beginner
Introduction To Statistics
>>Series和DataFrame好用的原因在于有些函数可以直接用,索引可以切片以及传入布尔型数组,list则可能没有这些优势
#求均值的方式不如Series方便
car_speeds = [10,20,30,50,20]
earthquake_intensities = [2,7,4,5,8]
mean_car_speed = sum(car_speeds) / len(car_speeds)
mean_earthquake_intensities = sum(earthquake_intensities) / len(earthquake_intensities)
#对数据进行标度
# Results from our survey on how many cigarettes people smoke per day
survey_responses = ["none", "some", "a lot", "none", "a few", "none", "none"]
survey_scale = ["none", "a few", "some", "a lot"]
survey_numbers = [survey_scale.index(response) for response in survey_responses]
average_smoking = sum(survey_numbers) / len(survey_numbers)
#画统计直方图及定义直方图的区间范围
average_speed = [10, 20, 25, 27, 28, 22, 15, 18, 17]
import matplotlib.pyplot as plt
plt.hist(average_speed)
plt.show()
plt.hist(average_speed, bins=6)
plt.show()
#求解分布的不对称度
from scipy.stats import skew
speed_skew=skew(average_speed)
#反映分布的锋利平滑程度,顶部的峰度越大越尖越小越平
from scipy.stats import kurtosis
kurt_platy=kurtosis(test_scores_platy)
#中位数median和均值不一样,前者是把样本进行排序选出中间的数,不容易受极端偏离值的影响
import numpy
plt.hist(test_scores_positive)
plt.axvline(numpy.median(test_scores_positive),color='b')
plt.axvline(test_scores_positive.mean(),color='r') # test_scores_positive是ndarray,所以可以用mean()
plt.show()
#针对titanic数据集进行清洗以及统计
import pandas
f = "titanic_survival.csv"
titanic_survival = pandas.read_csv(f)
new_titanic_survival = titanic_survival.dropna(subset=["age", "sex"])
import matplotlib.pyplot as plt
import numpy
plt.hist(new_titanic_survival['age'])
plt.axvline(numpy.median(new_titanic_survival['age']),c='b')
plt.axvline(new_titanic_survival['age'].mean(),c='r')
plt.show()
from scipy.stats import skew
from scipy.stats import kurtosis
mean_age=new_titanic_survival['age'].mean()
median_age=numpy.median(new_titanic_survival['age'])
skew_age=skew(new_titanic_survival['age'])
kurtosis_age=kurtosis(new_titanic_survival['age'])Standard Deviation and Correlation
#计算统计数据的方差,nba_stats是读取进来的DataFrame数据
import matplotlib.pyplot as plt
import pandas as pd
pts_mean=nba_stats["pts"].mean()
pts_var=[(i-pts_mean)**2 for i in nba_stats["pts"]]
point_variance=sum(pts_var)/len(pts_var)
#计算正态分布,产生在-10到10之间均值为0,方差为2的正态分布
from scipy.stats import norm
points=np.arange(-10,10,0.1)
probability=norm.pdf(points,0,2)
plt.plot(points,probability)
plt.show()
#计算相关,最常用pearsonr方式的r值
from scipy.stats.stats import pearsonr
# The pearsonr function will find the correlation between two columns of data.
# It returns the r value and the p value. We'll learn more about p values later on.
r, p_value = pearsonr(nba_stats["fga"], nba_stats["pts"])
#手动计算两个向量的协方差
# We've already loaded the nba_stats variable.
def covariance(x, y):
x_mean = sum(x) / len(x)
y_mean = sum(y) / len(y)
x_diffs = [i - x_mean for i in x]
y_diffs = [i - y_mean for i in y]
codeviates = [x_diffs[i] * y_diffs[i] for i in range(len(x))]
return sum(codeviates) / len(codeviates)
cov_stl_pf = covariance(nba_stats["stl"], nba_stats["pf"])
cov_fta_pts = covariance(nba_stats["fta"], nba_stats["pts"])
#利用pandas中相关函数计算方差numpy.cov(返回协方差矩阵)和标准差Series.std(),从而计算相关系数,即pearsonr中的r值
from numpy import cov
# We've already loaded the nba_stats variable for you.
r_fta_blk = cov(nba_stats["fta"], nba_stats["blk"])[0,1] / ((nba_stats["fta"].var() * nba_stats["blk"].var())** (1/2))
r_ast_stl = cov(nba_stats["ast"], nba_stats["stl"])[0,1] / ((nba_stats["ast"].var() * nba_stats["stl"].var())** (1/2))#画4*1的图,进行直方图统计
import matplotlib.pyplot as plt
import pandas as pd
movie_reviews = pd.read_csv("fandango_score_comparison.csv")
fig = plt.figure(figsize=(5,12))
ax1 = fig.add_subplot(4,1,1)
ax2 = fig.add_subplot(4,1,2)
ax3 = fig.add_subplot(4,1,3)
ax4 = fig.add_subplot(4,1,4)
ax1.set_xlim(0,5.0)
ax2.set_xlim(0,5.0)
ax3.set_xlim(0,5.0)
ax4.set_xlim(0,5.0)
movie_reviews["RT_user_norm"].hist(ax=ax1)
movie_reviews["Metacritic_user_nom"].hist(ax=ax2)
movie_reviews["Fandango_Ratingvalue"].hist(ax=ax3)
movie_reviews["IMDB_norm"].hist(ax=ax4)>>list不能直接对数值进行加减,而numpy和pandas的数据类型是可以的,如:a=[1,2,3] b=a+10是不允许的;而c=numpy.array([1,2,3]) d=c+10是允许的
>>计算线性回归的斜率
>>计算线性回归的b值
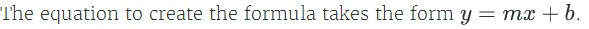

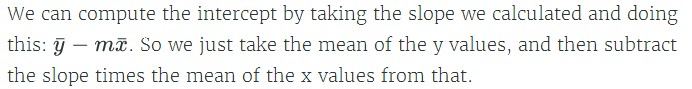
#计算线性回归的斜率,即利用协方差和方差计算两列元素之间的比值关系
# The wine quality data is loaded into wine_quality
from numpy import cov
slope_density=cov(wine_quality["quality"],wine_quality["density"])[0,1]/wine_quality["density"].var()
#计算截距
def calc_slope(x, y):
return cov(x, y)[0, 1] / x.var()
intercept_density = wine_quality["quality"].mean() - (calc_slope(wine_quality["density"],
wine_quality["quality"]) * wine_quality["density"].mean())
#进行数值预测
def calc_slope(x, y):
return cov(x, y)[0, 1] / x.var()
# Calculate the intercept given the x column, y column, and the slope
def calc_intercept(x, y, slope):
return y.mean() - (slope * x.mean())
slope = calc_slope(wine_quality["density"], wine_quality["quality"])
intercept = calc_intercept(wine_quality["density"], wine_quality["quality"], slope)
def compute_predicted_y(x):
return x * slope + intercept
predicted_quality=wine_quality["density"].apply(predict)
#使用scipy库构造线性回归,包括计算标准偏差
from scipy.stats import linregress
slope, intercept, r_value, p_value, stderr_slope = linregress(wine_quality["density"], wine_quality["quality"])
predicted_y = np.asarray([slope * x + intercept for x in wine_quality["density"]])
residuals = (wine_quality["quality"] - predicted_y) ** 2
rss = sum(residuals)
std_err=(rss/(len(residuals)-2))**(1/2)
ll=len(residuals)
one=[i for i in range(ll) if predicted_y[i]-wine_quality["quality"][i]<=std_err and predicted_y[i]-wine_quality.loc[i,"quality"]>=-std_err]
within_one=len(one)/len(residuals)
two=[i for i in range(ll) if predicted_y[i]-wine_quality.loc[i,"quality"]<=2*std_err and predicted_y[i]-wine_quality.loc[i,"quality"]>=-2*std_err]
within_two=len(two)/len(residuals)
three=[i for i in range(ll) if predicted_y[i]-wine_quality.loc[i,"quality"]<=3*std_err and predicted_y[i]-wine_quality.loc[i,"quality"]>=-3*std_err]
within_three=len(three)/len(residuals)
>>Series.idxmin()返回最小值索引,.idxmax()返回最大值索引。
>>对于list求均值方差以及标准差等,可以使用numpy.mean(list) numpy.var(list) numpy.std(list)
>>利用random库进行采样
lowest_income_county = income["county"][income["median_income"].idxmin()]
high_pop = income[income["pop_over_25"] > 500000]
lowest_income_high_pop_county = high_pop["county"][high_pop["median_income"].idxmin()]
>>random操作
import random
# Returns a random integer between the numbers 0 and 10, inclusive.
num = random.randint(0, 10)
# Generate a sequence of 10 random numbers between the values of 0 and 10.
random_sequence = [random.randint(0, 10) for _ in range(10)]
# Sometimes, when we generate a random sequence, we want it to be the same sequence whenever the program is run.
# An example is when you use random numbers to select a subset of the data, and you want other people
# looking at the same data to get the same subset.
# We can ensure this by setting a random seed.
# A random seed is an integer that is used to "seed" a random number generator.
# After a random seed is set, the numbers generated after will follow the same sequence.
random.seed(10)
print([random.randint(0,10) for _ in range(5)])
random.seed(10)
# Same sequence as above.
print([random.randint(0,10) for _ in range(5)])
random.seed(11)
# Different seed means different sequence.
print([random.randint(0,10) for _ in range(5)])
# Let's say that we have some data on how much shoppers spend in a store.
shopping = [300, 200, 100, 600, 20]
# We want to sample the data, and only select 4 elements.
random.seed(1)
shopping_sample = random.sample(shopping, 4)
# 4 random items from the shopping list.
print(shopping_sample)
import matplotlib.pyplot as plt
# A function that returns the result of a die roll.
def roll():
return random.randint(1, 6)
random.seed(1)
small_sample = [roll() for _ in range(10)]
# Plot a histogram with 6 bins (1 for each possible outcome of the die roll)
random.seed(1)
medium_sample=[roll() for _ in range(100)]
plt.hist(medium_sample,bins=6)
plt.show()该部分官方提供的代码 here
求绝对值函数numpy.absolute 或者numpy.abs()
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as st
movies=pd.read_csv("fandango_score_comparison.csv")
#plt.hist(movies["Metacritic_norm_round"])
#plt.show()
#plt.hist(movies["Fandango_Stars"])
#plt.show()
mean_f=movies["Fandango_Stars"].mean()
mean_m=movies["Metacritic_norm_round"].mean()
median_f=movies["Fandango_Stars"].median()
median_m=movies["Metacritic_norm_round"].median()
std_dev_f=movies["Fandango_Stars"].std()
std_dev_m=movies["Metacritic_norm_round"].std()
#print(mean_f,mean_m)
#print(median_f,median_m)
print(std_dev_f,std_dev_m)
movies.plot.scatter(x="Fandango_Stars",y="Metacritic_norm_round")
plt.show()
movies["fm_diff"]=movies["Metacritic_norm_round"]-movies["Fandango_Stars"]
movies["fm_diff"]=np.absolute(movies["fm_diff"])
movies.sort_values("fm_diff",inplace=True,ascending=False)
#print(movies.head())
r,p=st.pearsonr(movies["Fandango_Stars"],movies["Metacritic_norm_round"])
print(r)
slope, intercept, r_value, p_value, stderr_slope =st.linregress(movies["Metacritic_norm_round"],movies["Fandango_Stars"])
print(slope,r)
pred_3=slope*3.0+intercept
print(pred_3)
pred_1=slope*1.0+intercept
pred_5=slope*5.0+intercept
x=[1.0,5.0]
y=[slope*i+intercept for i in x]
movies.plot.scatter(x="Metacritic_norm_round",y="Fandango_Stars")
plt.plot(x,y)
plt.xlim(1,5)
plt.show()













 4470
4470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









