







1 什么是爬虫
把互联网比喻成一张网,那么爬虫就是网上爬行的蜘蛛,把网的节点比喻成一个个网页,爬虫爬取到就相当于访问了该页面,获取了其信息,爬虫可以通过一个节点之后,顺着节点连线(链接) 继续爬行到下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点就可以被爬虫全部爬到。
实际实现可理解为:网络爬虫(又称网页蜘蛛,网络机器人)模拟浏览器发送网络请求,接收请求响应,按照一定的规则,自动地抓取互联网信息的程序。

简而言之:爬虫就是获取网页并提取和保存信息的自动化程序。(原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。)
爬虫的应用:
-
网站上的投票
-
短信轰炸
2. 爬虫的分类
根据被爬网站的数量的不同,我们把爬虫分为:
-
通用爬虫 :通常指搜索引擎的爬虫(https://www.baidu.com)
-
聚焦爬虫 :针对特定网站的爬虫
3. 爬虫的流程
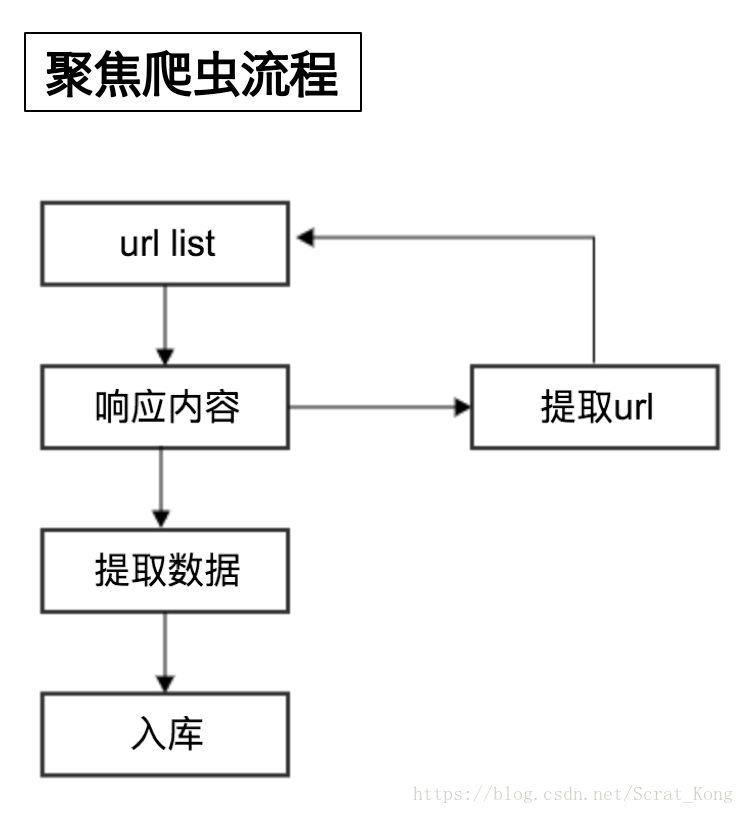
- 向起始url发送请求,并获取响应
- 对响应进行提取
- 如果提取url,则继续发送请求获取响应
- 如果提取数据,则将数据进行保存
关于获取网页:
爬虫的首要工作就是获取网页,即获取网页源代码,python提供了很多库来帮助我们实现发请求、获取网页响应的操作,如urllib、requests(会在后续文章中进行介绍)。我们可用这些库来帮助我们实现HTTP操作。
关于提取信息:
网页中信息冗杂,我们不会全都需要,就要把获得的数据进行提取筛选,网页的结构有一定的规则,还有一些可以根据网页节点属性、CSS选择器、XPath来提取网页信息的库,如Beautiful Soup、 pyquery、lxml等,使用这些库可以快速高效的从中提取网页信息。
关于保存数据:
提取信息后就需要对提取到的数据保存到某处方便后续使用,保存的形式多种多样,TXT、JSON or in DB , such as MySQL and MongoDB 。
4. robots协议
在百度搜索中,不能搜索到淘宝网中某一个具体的商品的详情页面,这就是robots协议在起作用
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的一般约定
例如:淘宝的robots协议
小结
- 数据的来源:
- 去第三方的公司购买数据
- 去免费的数据网站下载数据(比如国家统计局)
- 通过爬虫爬取数据
- 人工收集数据(比如问卷调查)
- 爬虫的概念:模拟浏览器发送网络请求,接收请求响应
- 爬虫分类:通用爬虫、聚焦爬虫
- 爬虫的流程:
- 向起始url发送请求,并获取响应
- 对响应进行提取
- 如果提取url,则继续发送请求获取响应
- 如果提取数据,则将数据进行保存
- robots协议:无需遵守该协议
进一步了解爬虫:请看 爬虫(一)爬虫入门

Scrat 一个热爱坚果的松鼠哦~














 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









