







反向传播(back propagation)算法详解
反向传播算法是神经网络的基础之一,该算法主要用于根据损失函数来对网络参数进行优化,下面主要根据李宏毅机器学习课程来整理反向传播算法,原版视频在https://www.bilibili.com/video/av10590361/?p=14.
首先,我们来看一看优化方程:
![]()
上面的损失函数是普通的交叉熵损失函数,然后加上了正则化项,为了更新参数W,我们需要知道J关于W的偏导。

上图是一个简单的例子,我们截取神经网络的一部分,根据链式法则(chain rule),要想知道J关于w的偏导,我们需要求出:
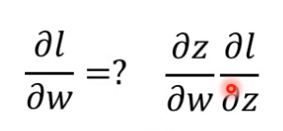
上面的式子也可以写成下式,a代表activation function也就是激活函数:
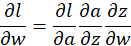
1:前向传播(forward pass)
在前向传播中,我们可以得到每个神经元的输出z,以及z关于该层参数w的偏微分:

根据z的式子我们可以知道,z关于w的偏导等于该层的输入,下图是一个例子:

2:反向传播(backward pass)
通过正向传播,我们已经知道了![]() 但是
但是![]() 还没有求出来,而这两项都是在反向传播过程中得到的。
还没有求出来,而这两项都是在反向传播过程中得到的。
其中![]() 比较好求,因为它的值就是激活函数的偏导,比如sigmoid函数的偏导等于z(1-z).因此现在我们只需要求解
比较好求,因为它的值就是激活函数的偏导,比如sigmoid函数的偏导等于z(1-z).因此现在我们只需要求解![]() :
:

根据链式法则,![]() 等于所有分支关于a的偏导,如上图所示。
等于所有分支关于a的偏导,如上图所示。
因此求解![]() 的过程大致如下:
的过程大致如下:

为了求![]() ,我们需要求解
,我们需要求解![]() ,如果直接连接输出的话,可以按照下面求解:
,如果直接连接输出的话,可以按照下面求解:

如果不是直接输出,那么就递归的求解![]() 。
。

下面就是总的过程:

可以看出,在求解偏导的时候,需要乘以每一层的输出z,以及激活函数的导数,以及中间的参数w,因此在训练神经网络的时候需要做batch normalization,使得每一层的输入大致在一个scale下面,另外还需要加正则项防止w过大(会造成梯度爆炸),除此之外还需要设计一些好的激活函数来防止梯度消失问题(如sigmoid的偏导最大值为0.25,因此层数加深之后会造成梯度消失)。














 1387
1387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









