
So the prelim results for the NIJ recidivism challenge are up. My team, MCHawks with Gio Circo, did ok. Here is a breakdown of team winnings (minus the student category) per 1k. So while we won the most in the small team category, IdleSpeculation overall kicked our butt!
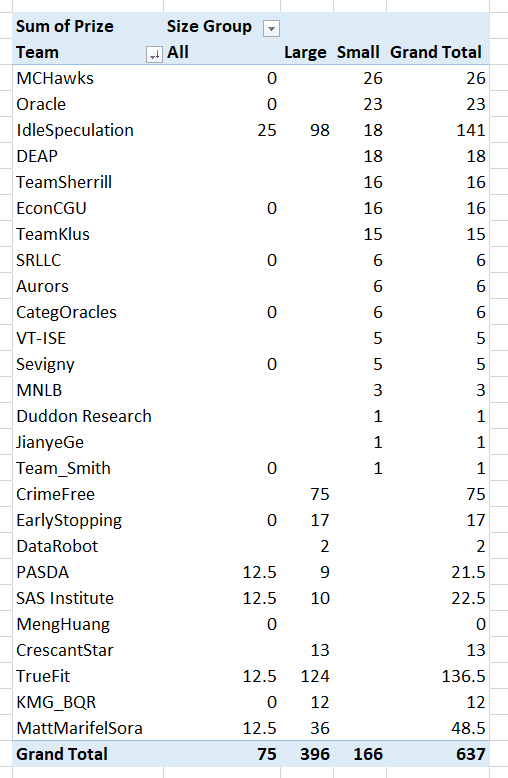
We actually biased our predictions to meet the racial fairness constraint, so you can see we did much better in those categories in Round 1 and Round 2. Unfortunately you only win if you get top in this category – no second place winners here (it says Brier score in these tables, but this is (1 - BrierScore)*(1 - FPDifference):
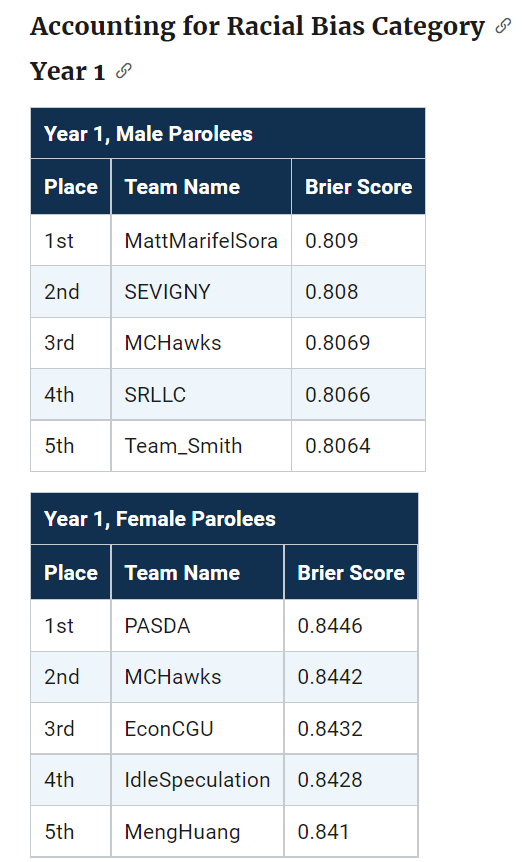
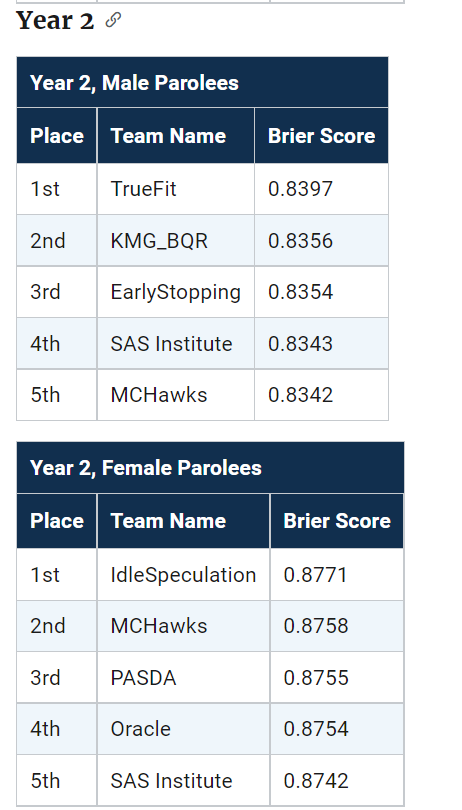
But we got lucky and won the overall in Round 2 despite biasing our predictions. Round 3 we have no excuse really, while the predictions were biased it did not matter.
We will do a paper for the results, but overall our approach is pretty standard. For each round we did a grid search over various models – for R1 and R3 we did a L1 logit, for R2 we did an XGBoost model. I did attempt a specialized Logit model with the fairness constraints in the loss function (and just used backpropogation to fit the model, ala deep learning), but in practice the way the fairness metric is done this just added noise into the estimate.
I will have more to say in the future about fairness metrics, unfortunately here I do not think it was well thought out. It was simply the false positive rate comparing white/black subgroups, assuming a threshold of 0.5, which does not make sense in practice. (I’ve written about calculating the threshold for bail here, it applies the same to parole though as well.) So for each model we simply clipped probabilities to be below 0.5 to meet this – no one predicted high means 0 false positives for each group.
So the higher threshold makes it silly, also the multiplication between the metrics I don’t think is a good idea either. I think it can be amended though to be a more reasonable additive fairness constraint. E.g. BrierScore + lambda*FPDifference, where lambda is a tuner to set how you want to make the tradeoff (and FP may be the total N difference, not a proportion difference, which can be volatile for small N). (Also I think it makes more sense to balance false negatives than false positives in the CJ example, but any algorithm to balance one can be flipped to balance the other.)
I do like how NIJ spreads prizes out, instead of Kaggle like with only 1/2/3 big prizes. I wish here we could submit two predictions though (one for main and one for fair). (I am pretty sure we would have placed in Year1 if we did not bias our predictions.)


4 Comments