









我们简单看下namenode启动需要经历的步骤。
namenode启动要做什么
启动9870服务端口
因为namenode是一个进程,所以找到它的main方法:
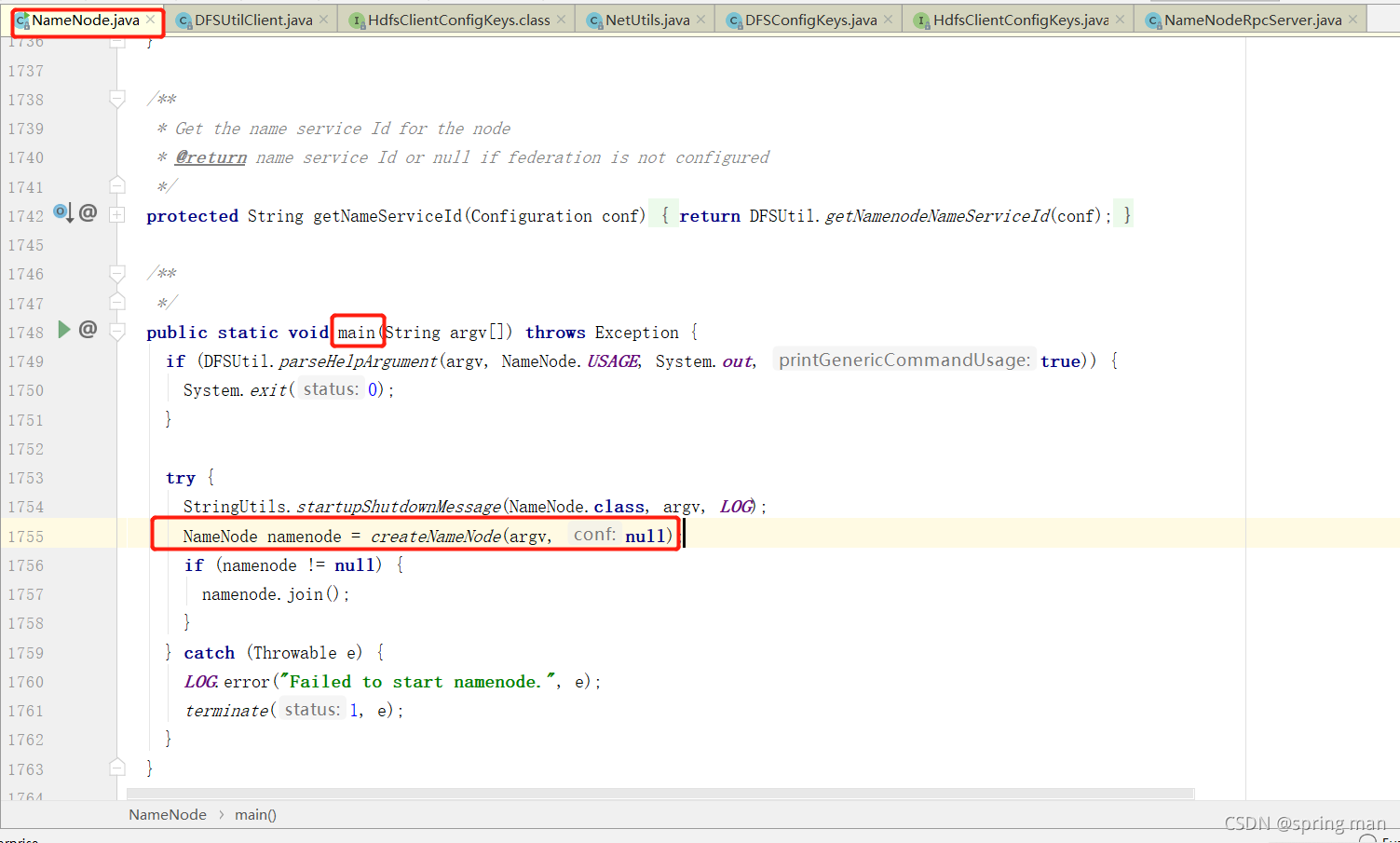
进入createNameNode:

找到new NodeNode(conf),进去。
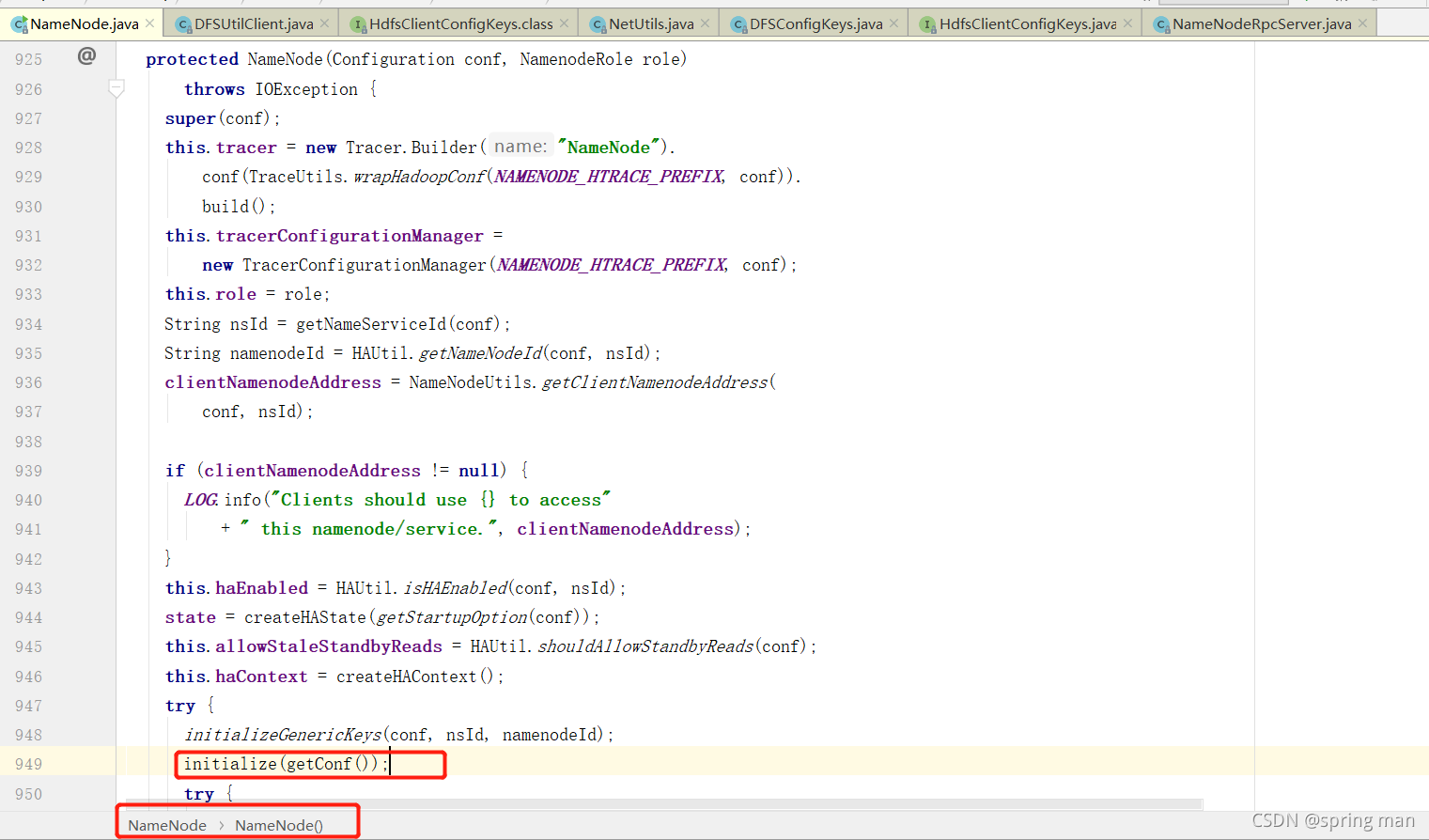
找到初始化方法,进入:
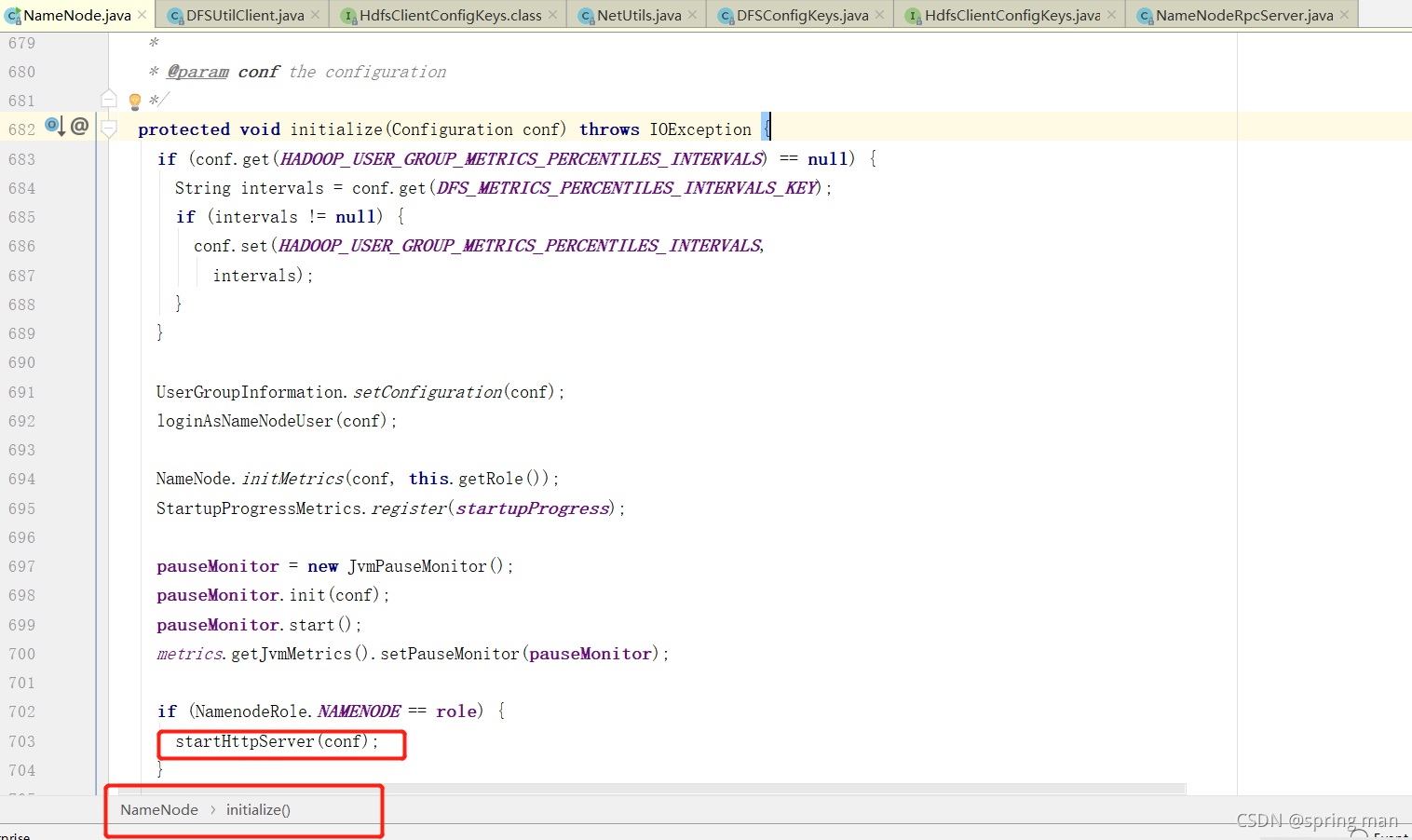
他要获取绑定的地址,我们希望知道这个地址是什么。

看看这个默认的地址:
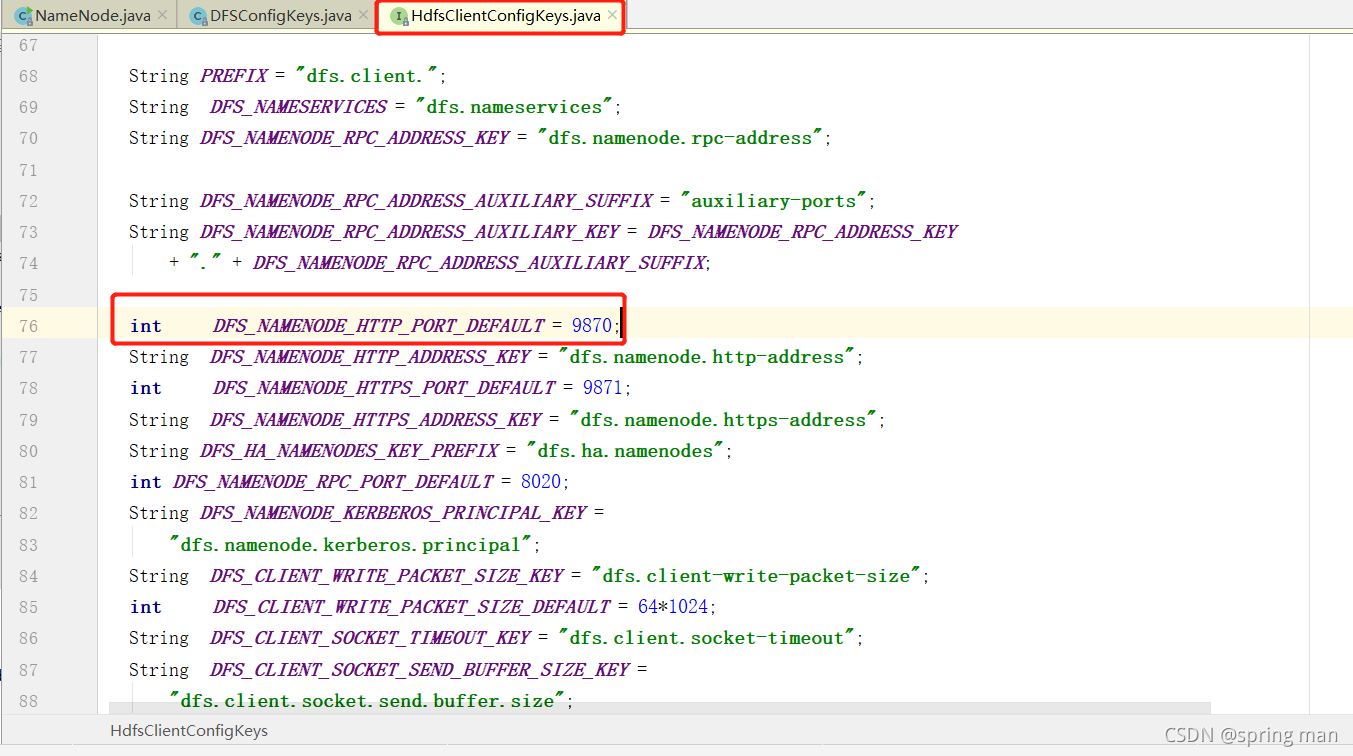
端口号是9870。这就是我们经常用的namenode的web端口。
加载镜像文件和编辑日志文件
回到初始化initialize方法:
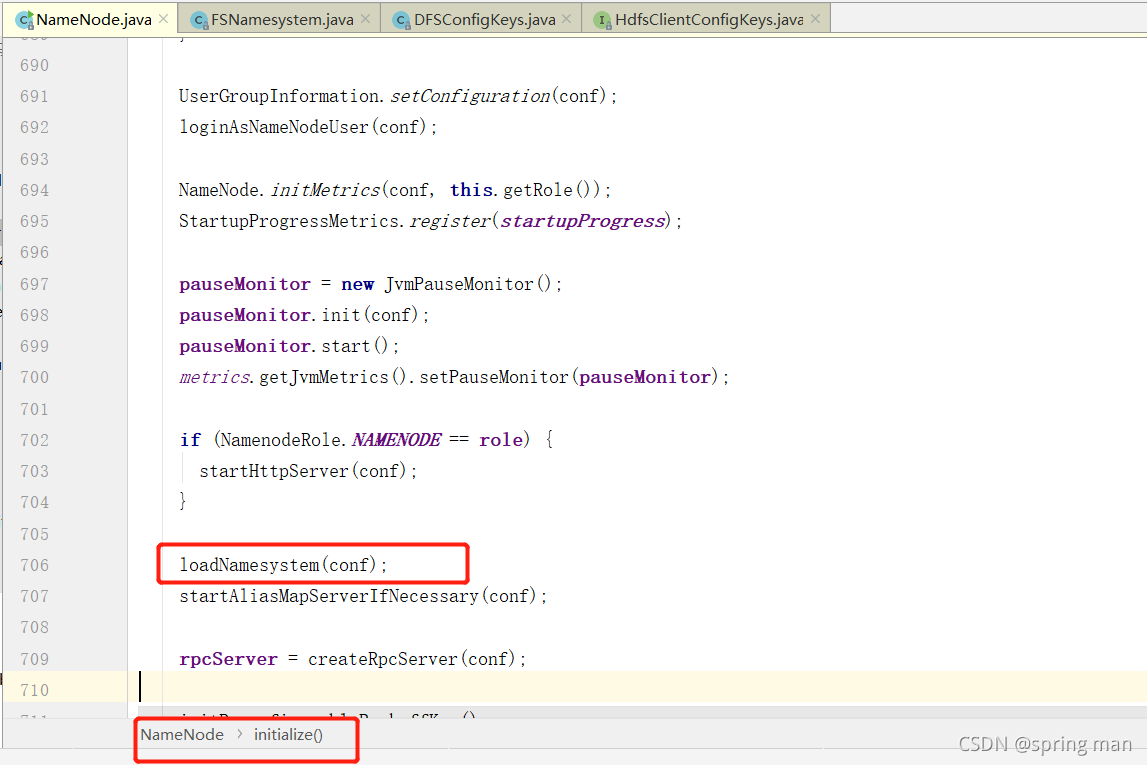
现在进入loadNamesystem(conf)。
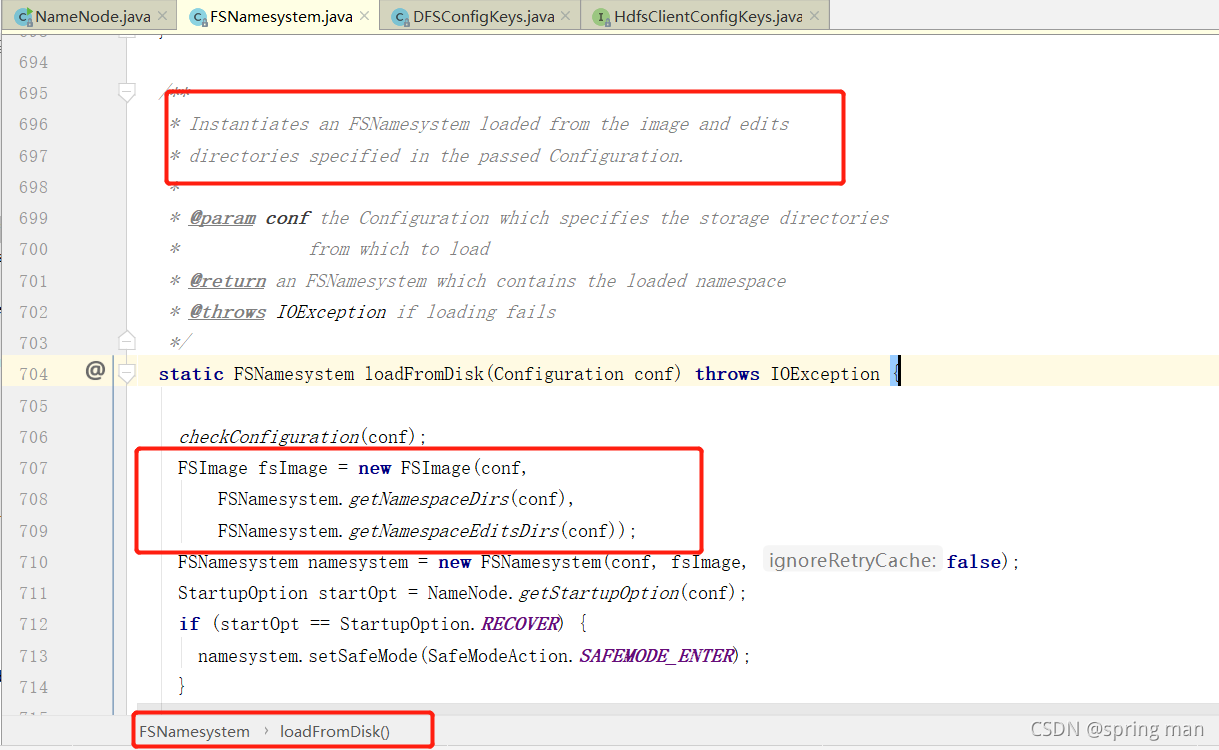
可以看到它同时将fsImage和edits文件加载到了内存,这里包含所有的数据。
初始化RPC服务
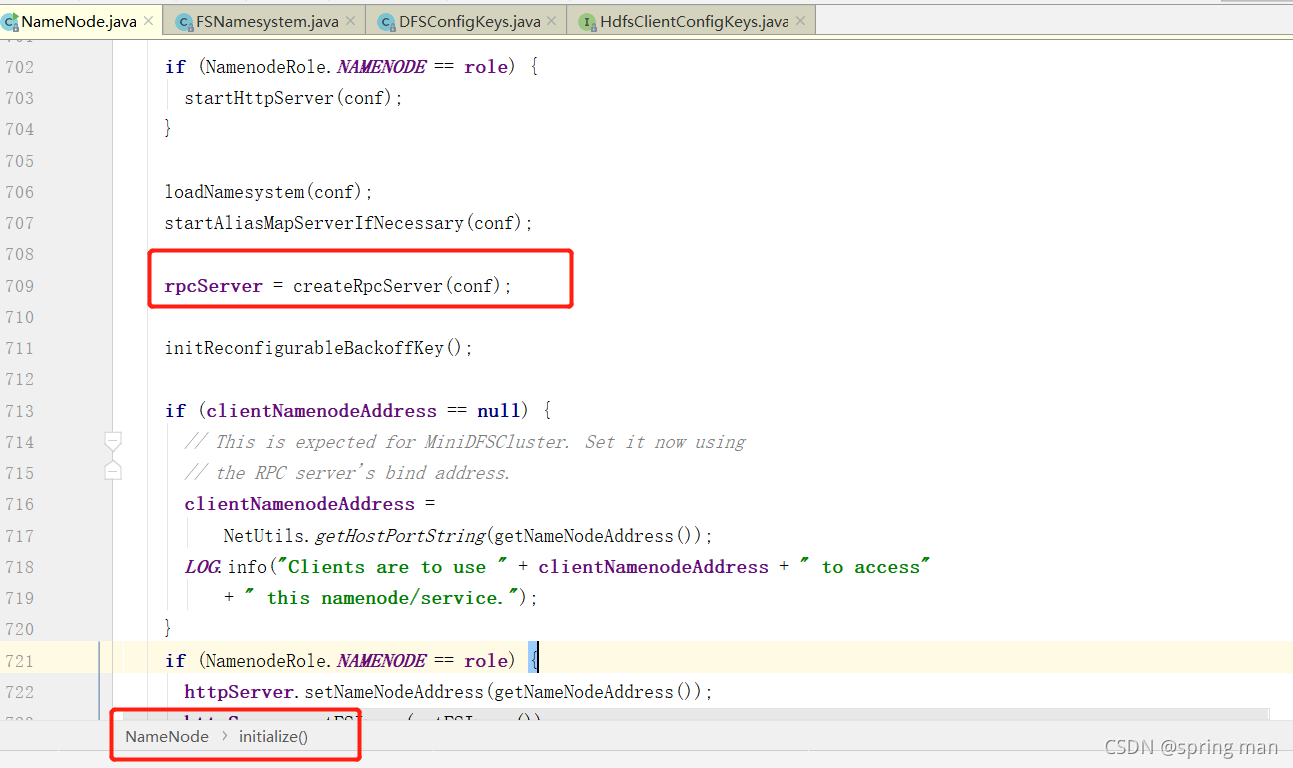
再回到初始化方法,进入createRpcServer(conf):
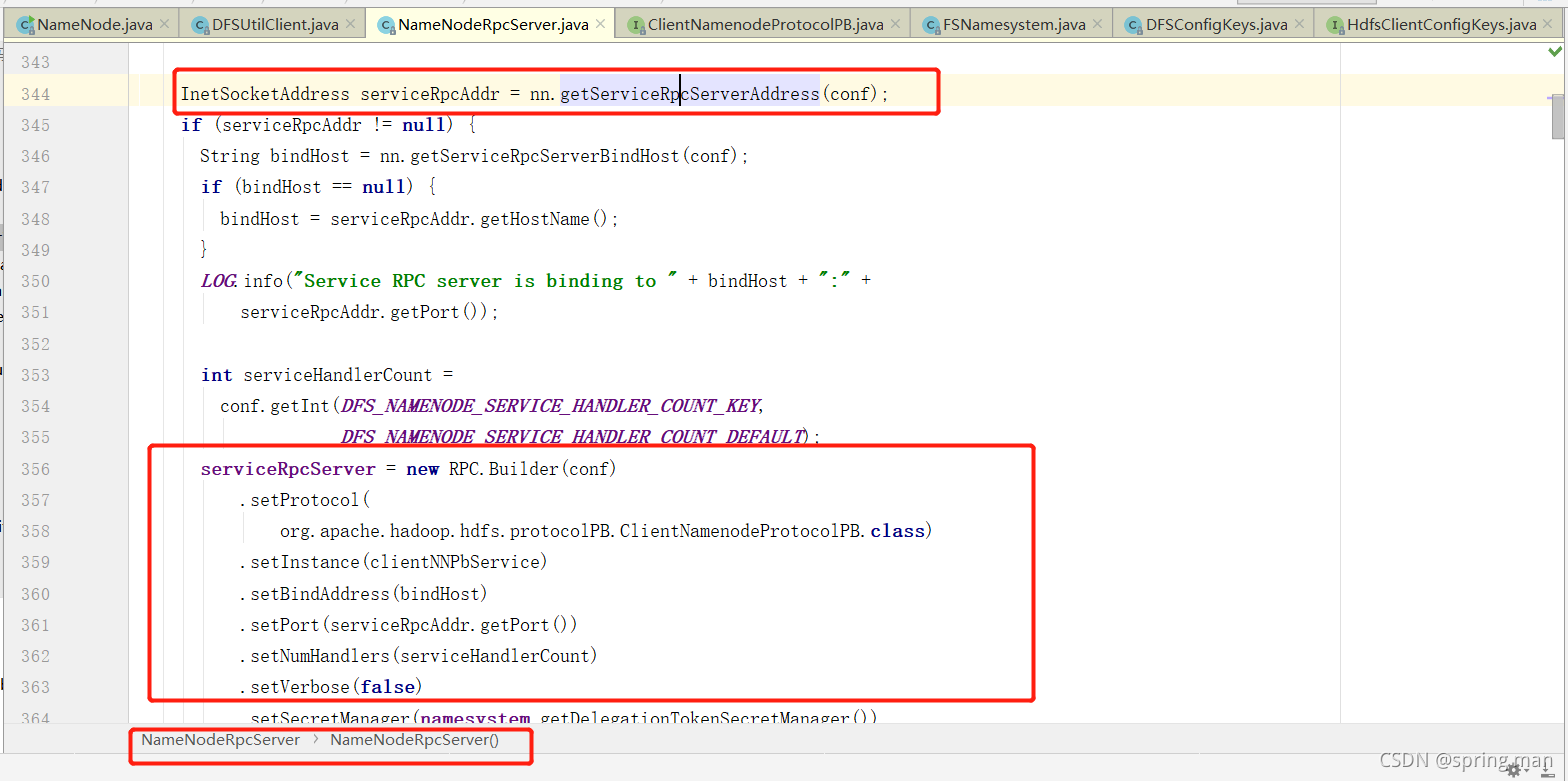
一直进入InetSocketAddress serviceRpcAddr = nn.getServiceRpcServerAddress(conf);可以了解到rpc的端口是8020(默认)。
同时,他用RPC Builder的模式构造了server端的服务。我们看看其中所使用的协议:
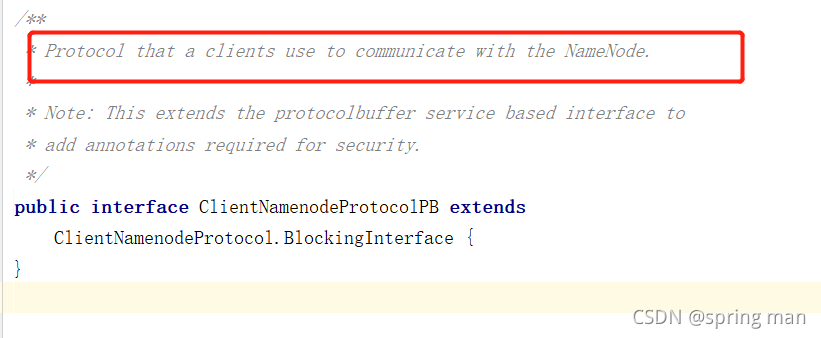
这是一个客户端用来通信的协议(和没说一样)。
启动资源检查
再次回到初始化代码,进入startCommonServices(conf);:
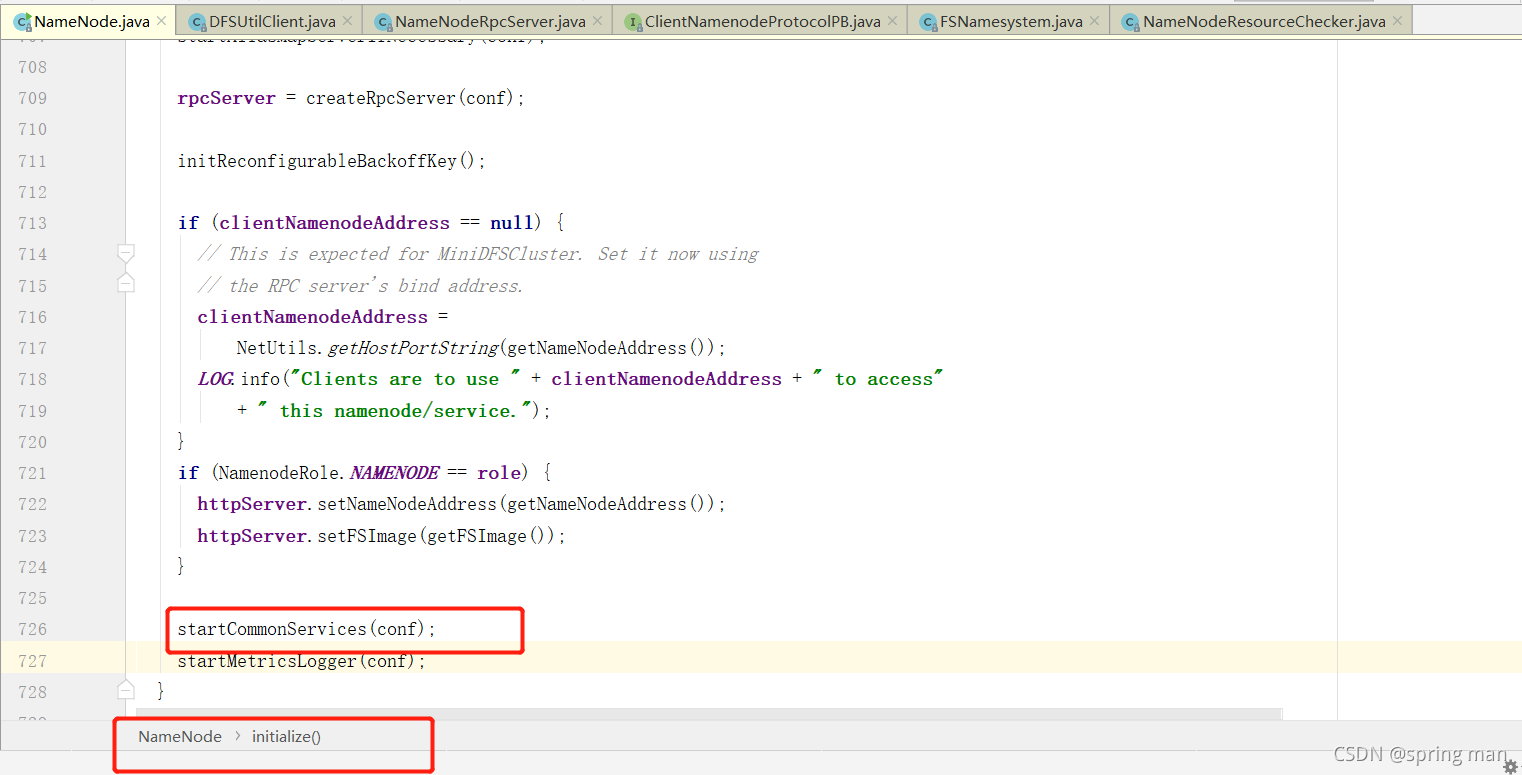
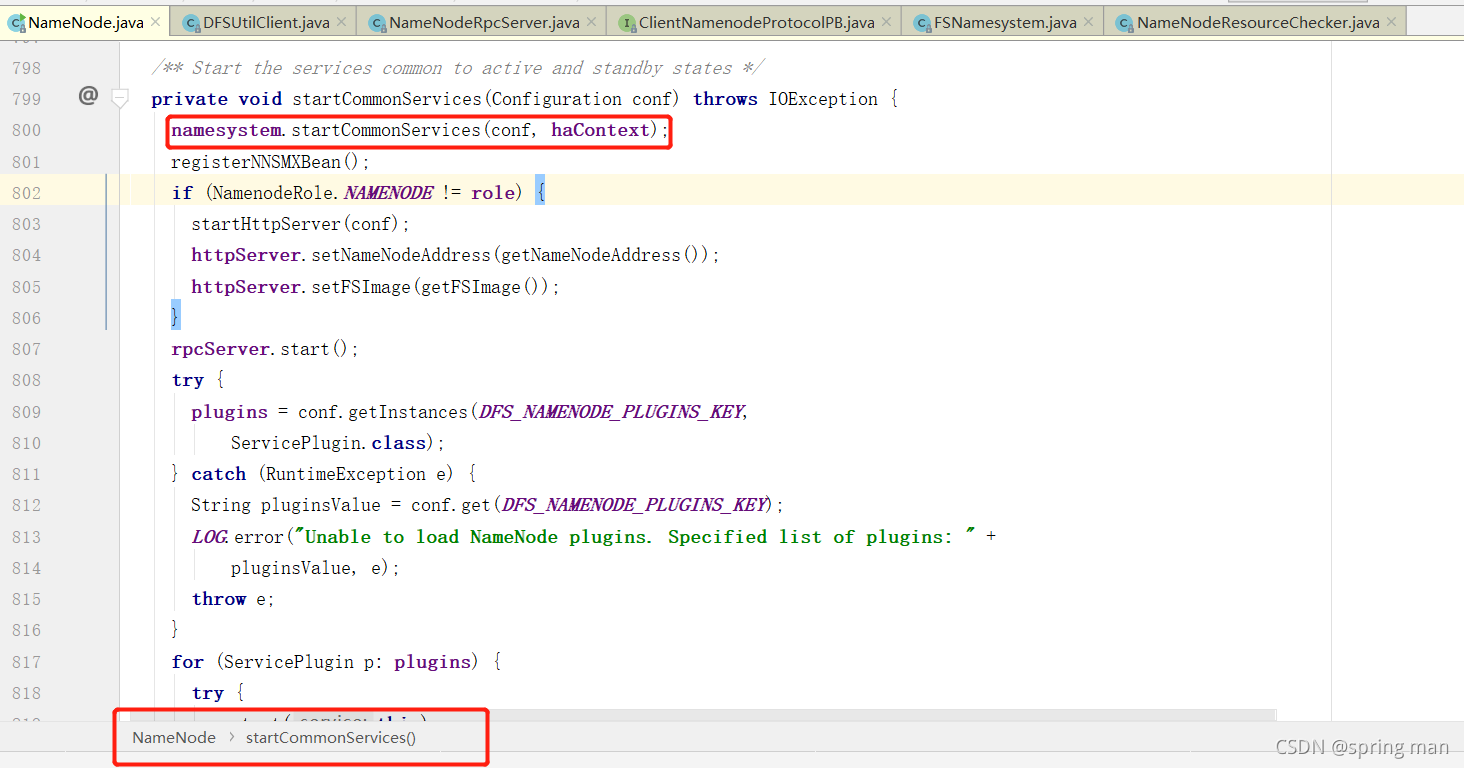
再进:
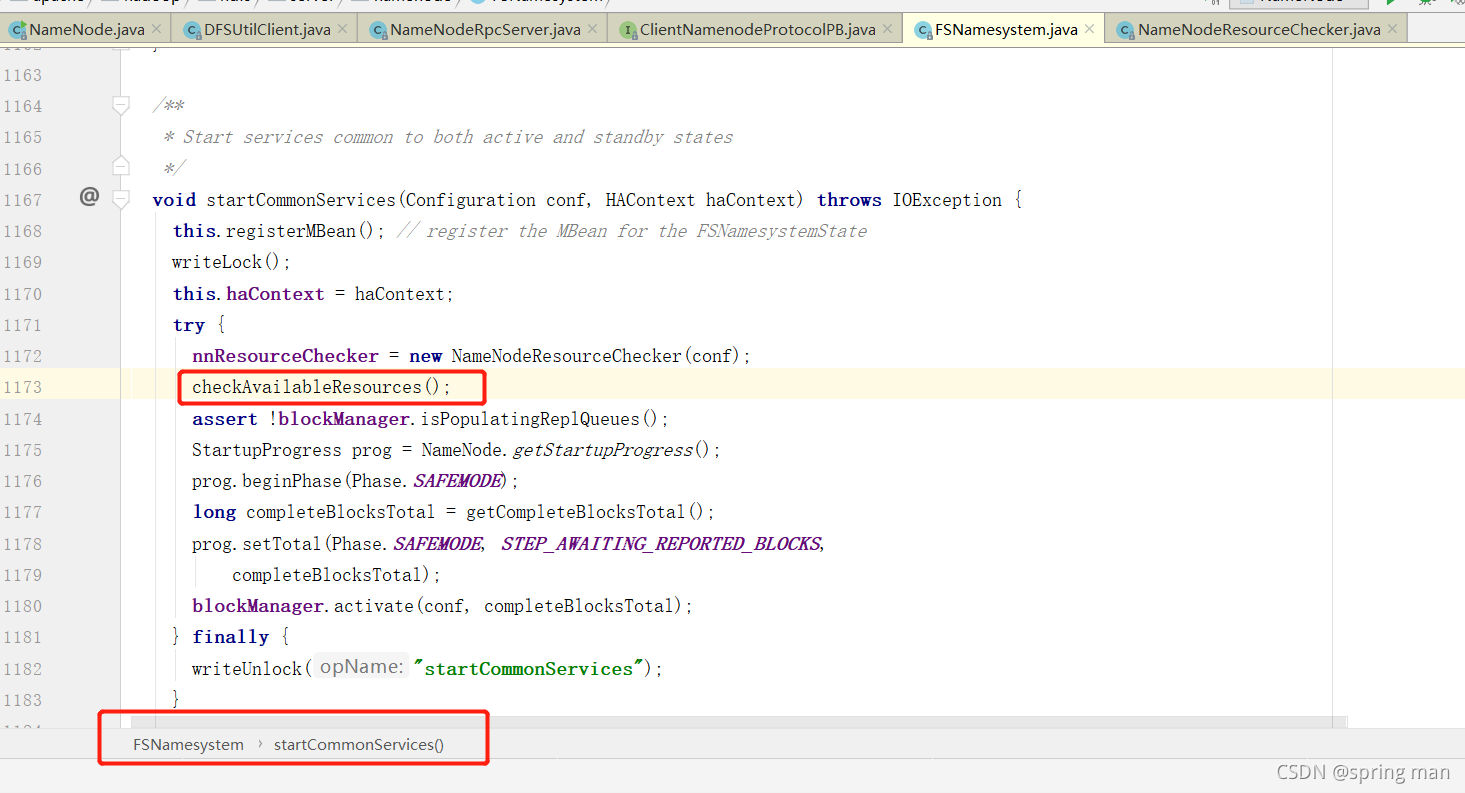
再进:

再进(一路走):
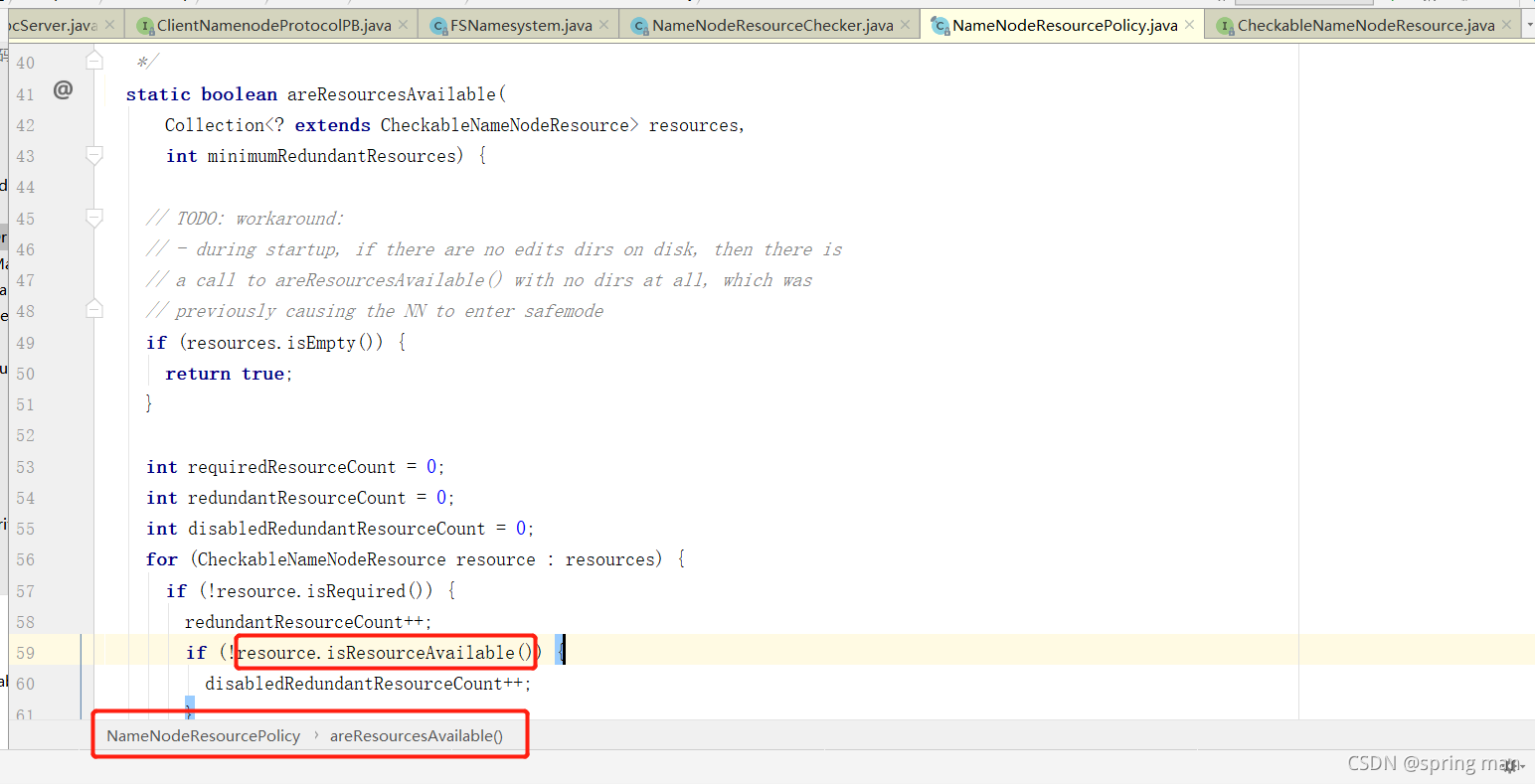
查看资源是否可用。
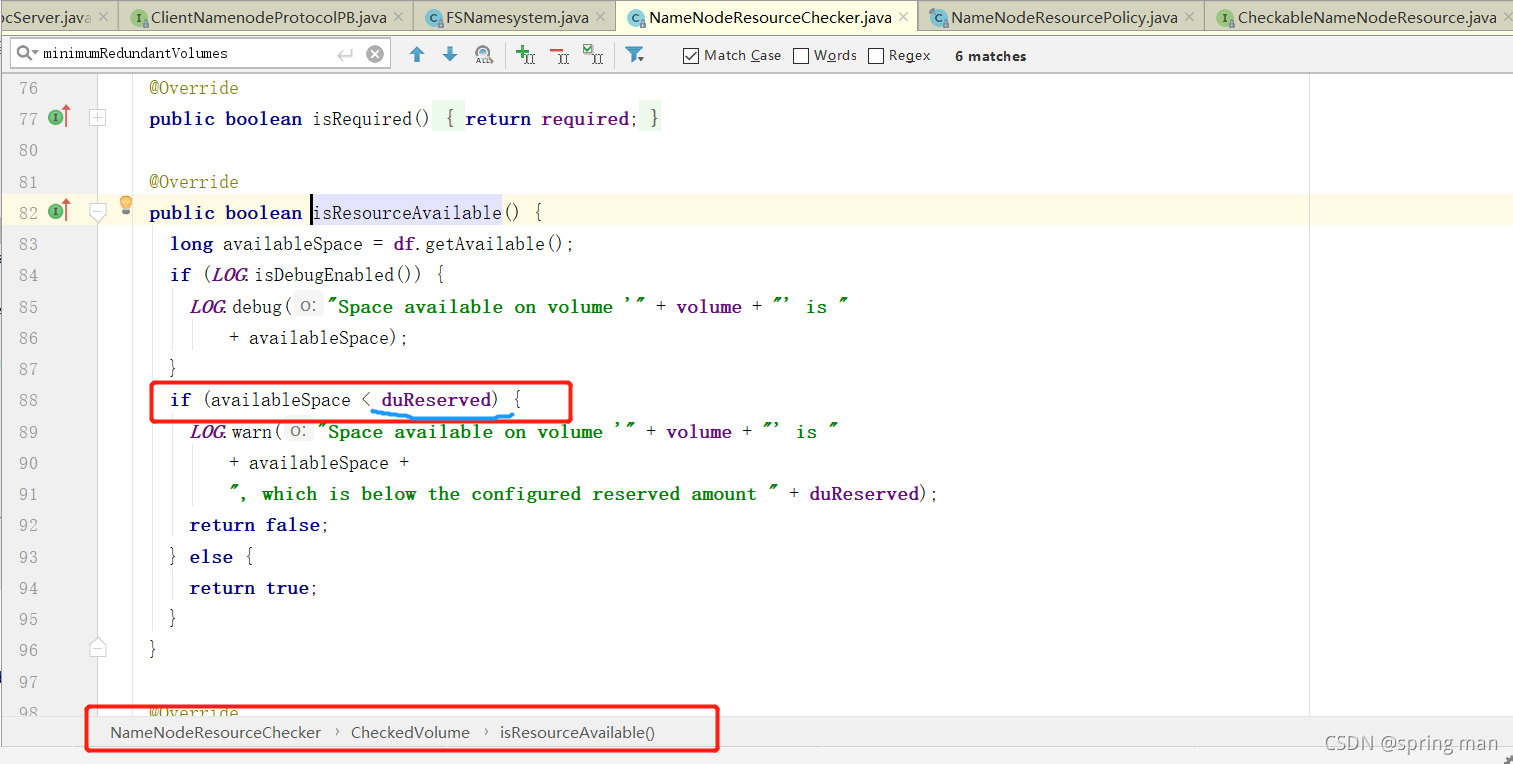
关键在于其中的一个常量。
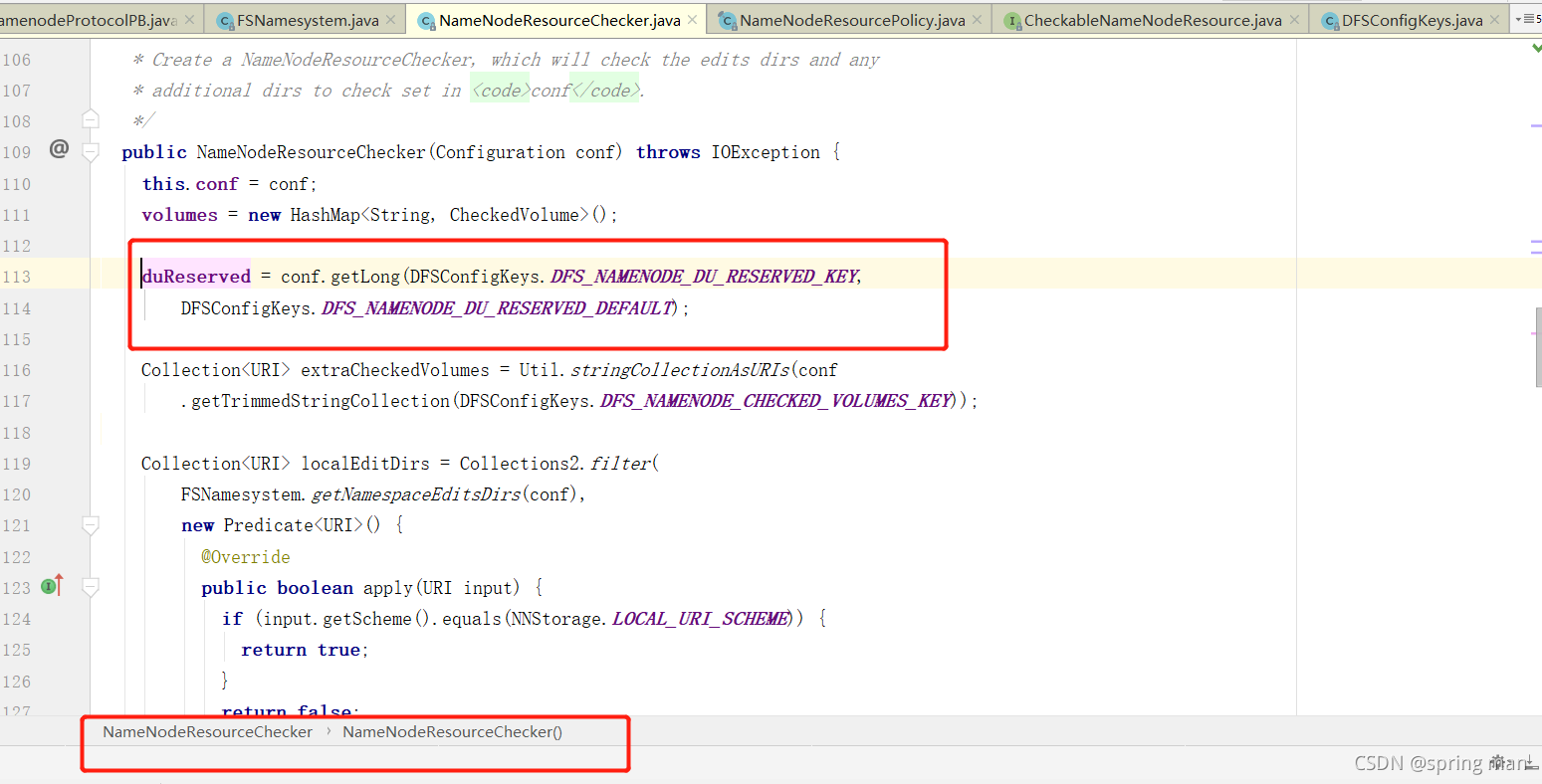
这个值默认是100M,也就是说,如果你磁盘不到100MB了,人家就要给你警告,说,再往edits写操作日志空间快不够啦。
检查心跳
回到检查资源最开始那里:
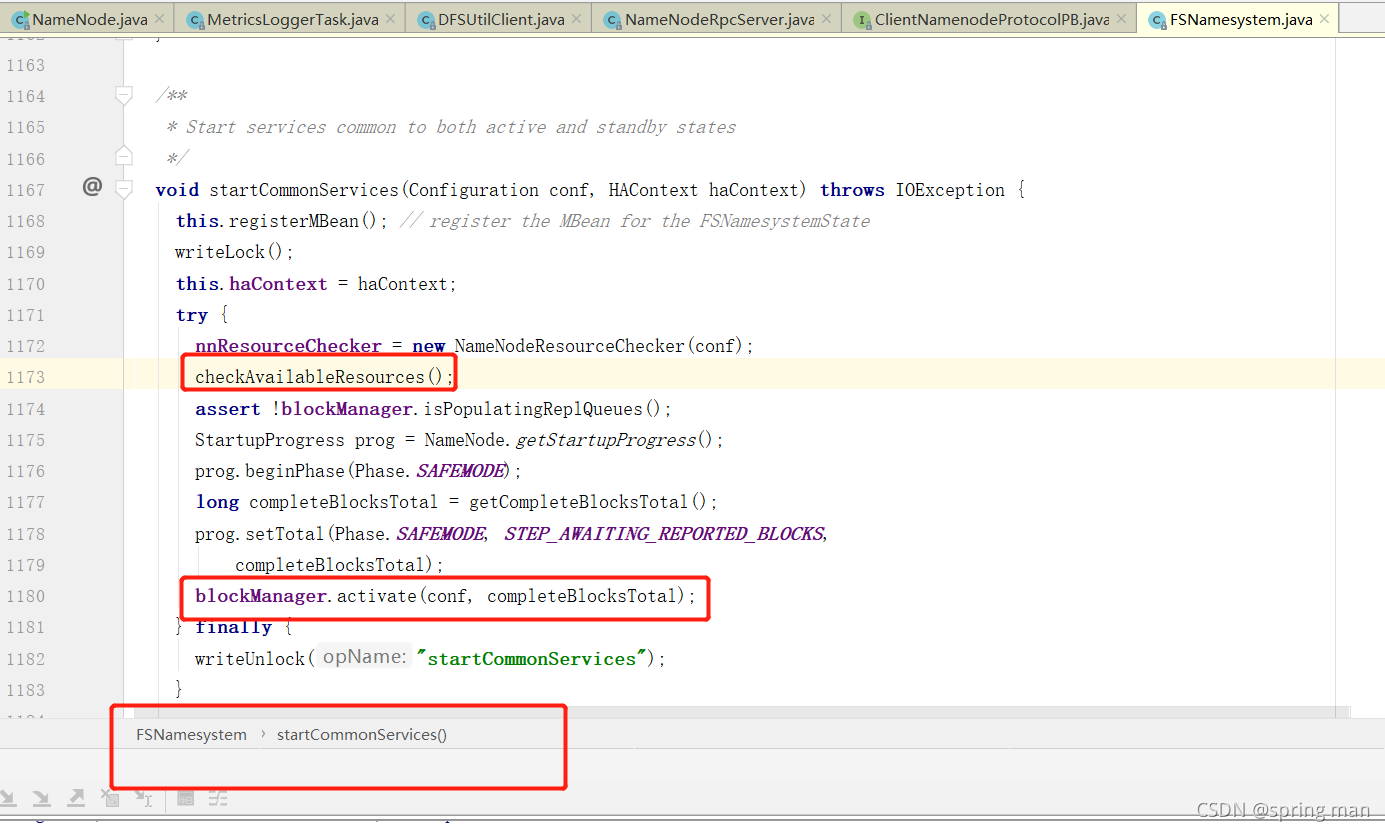
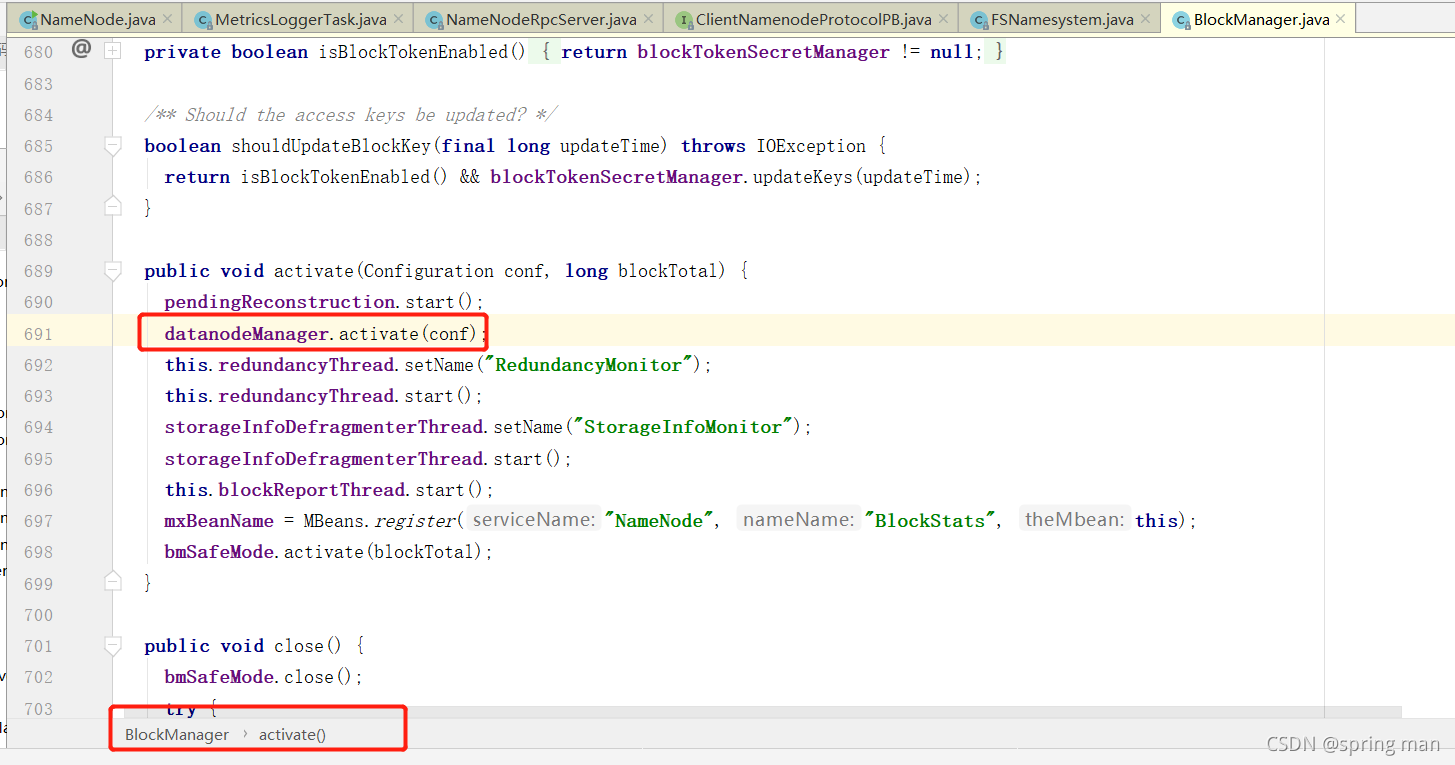
这个datanodeManager是用来管理NN和DN之间的联系的。
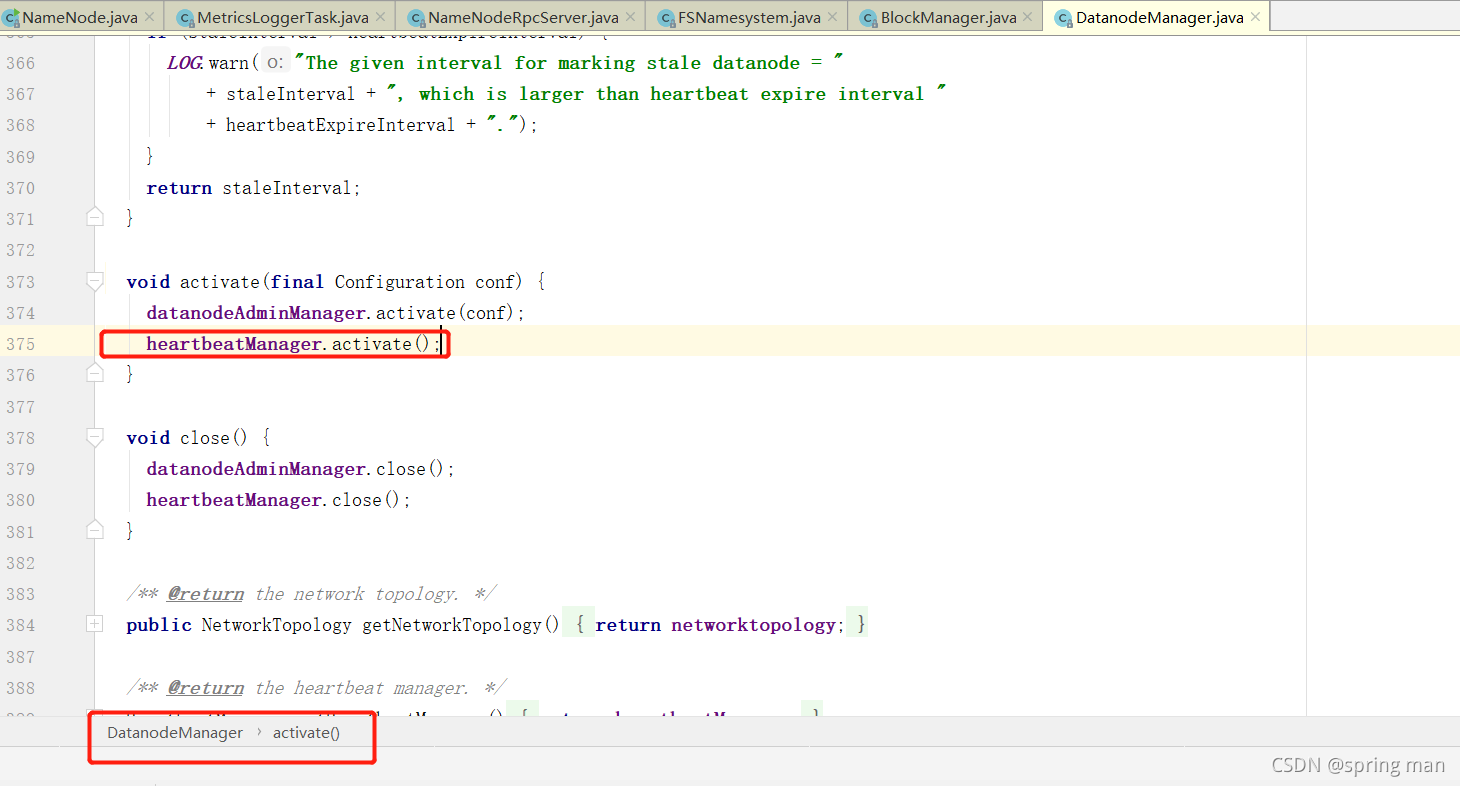
现在他要对心跳进行检测。
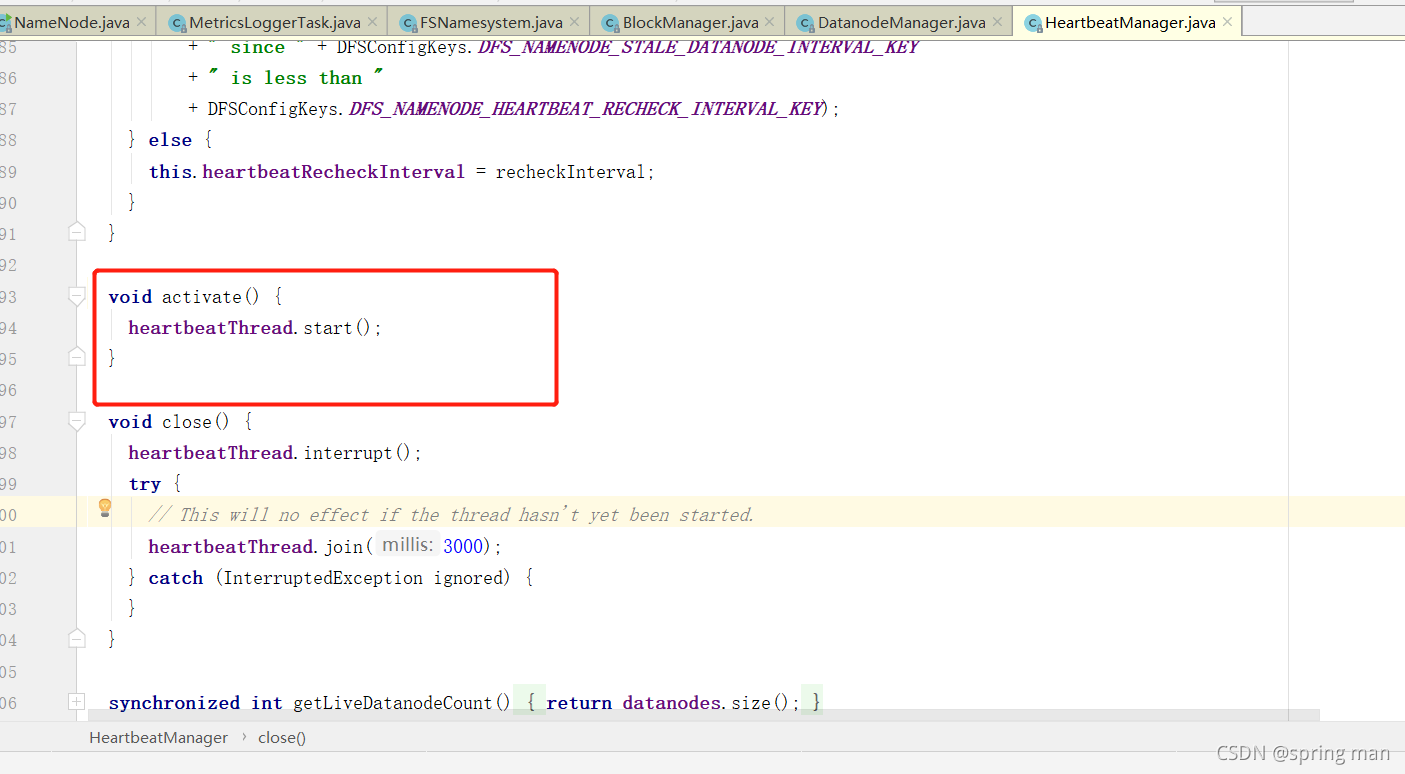
这是一个线程。
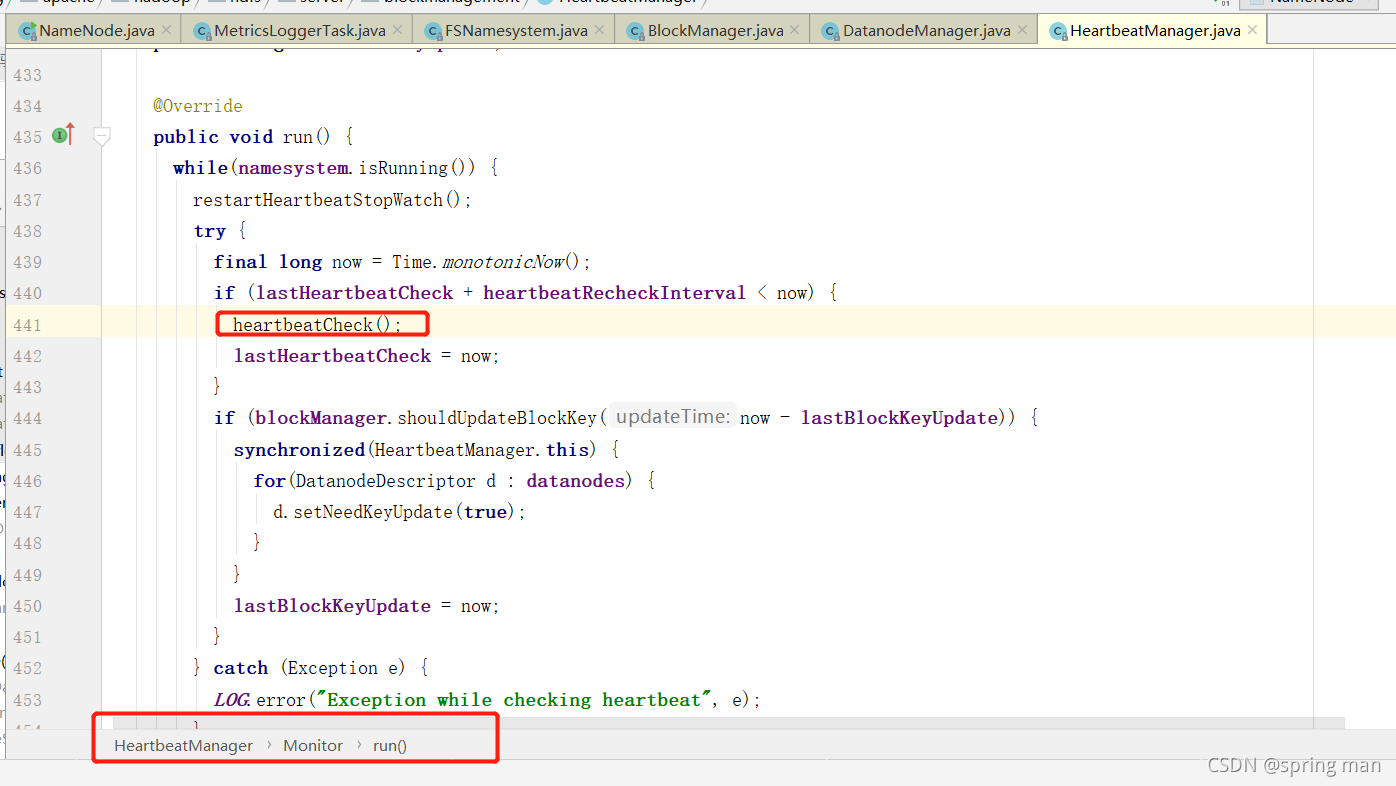
在run方法中找到检测心跳的逻辑。
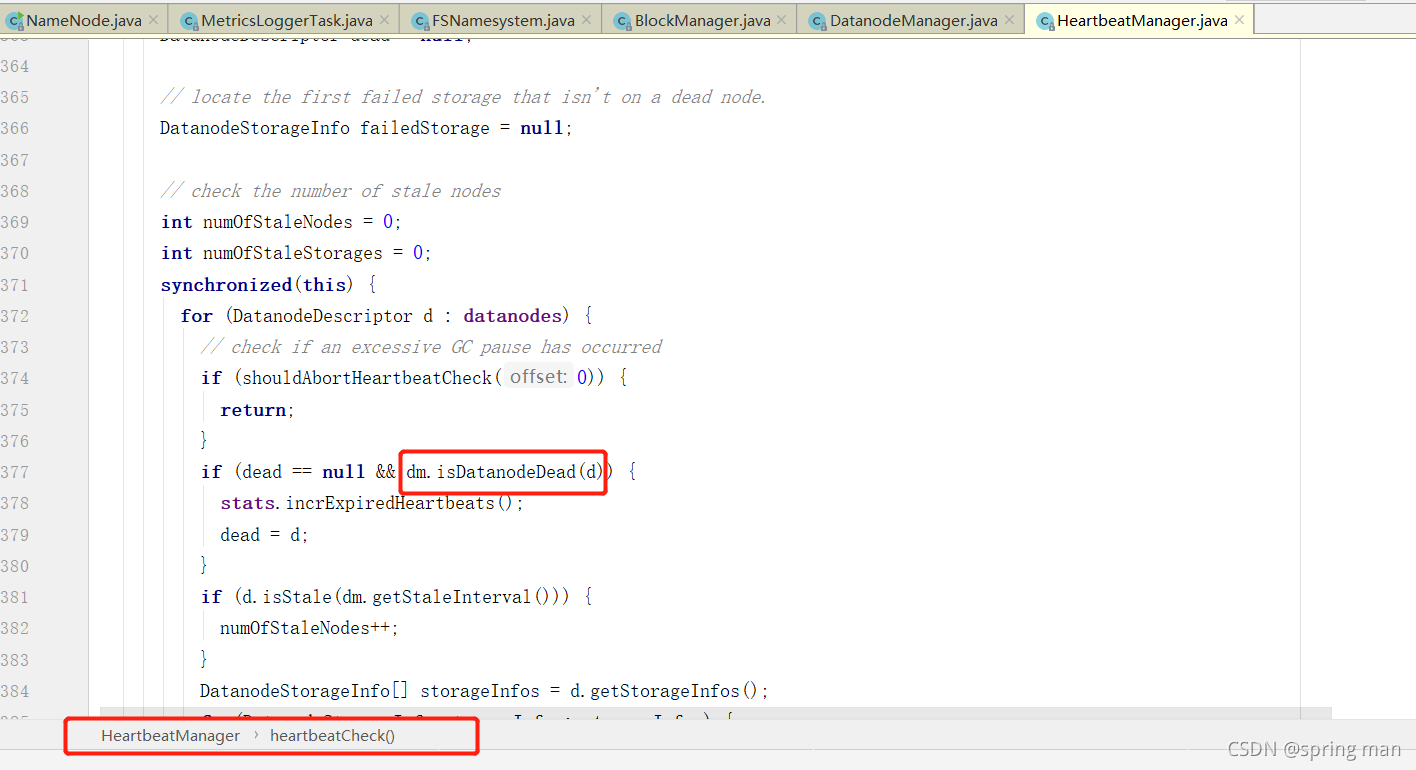
我们看他是如何判断DN的死亡的。
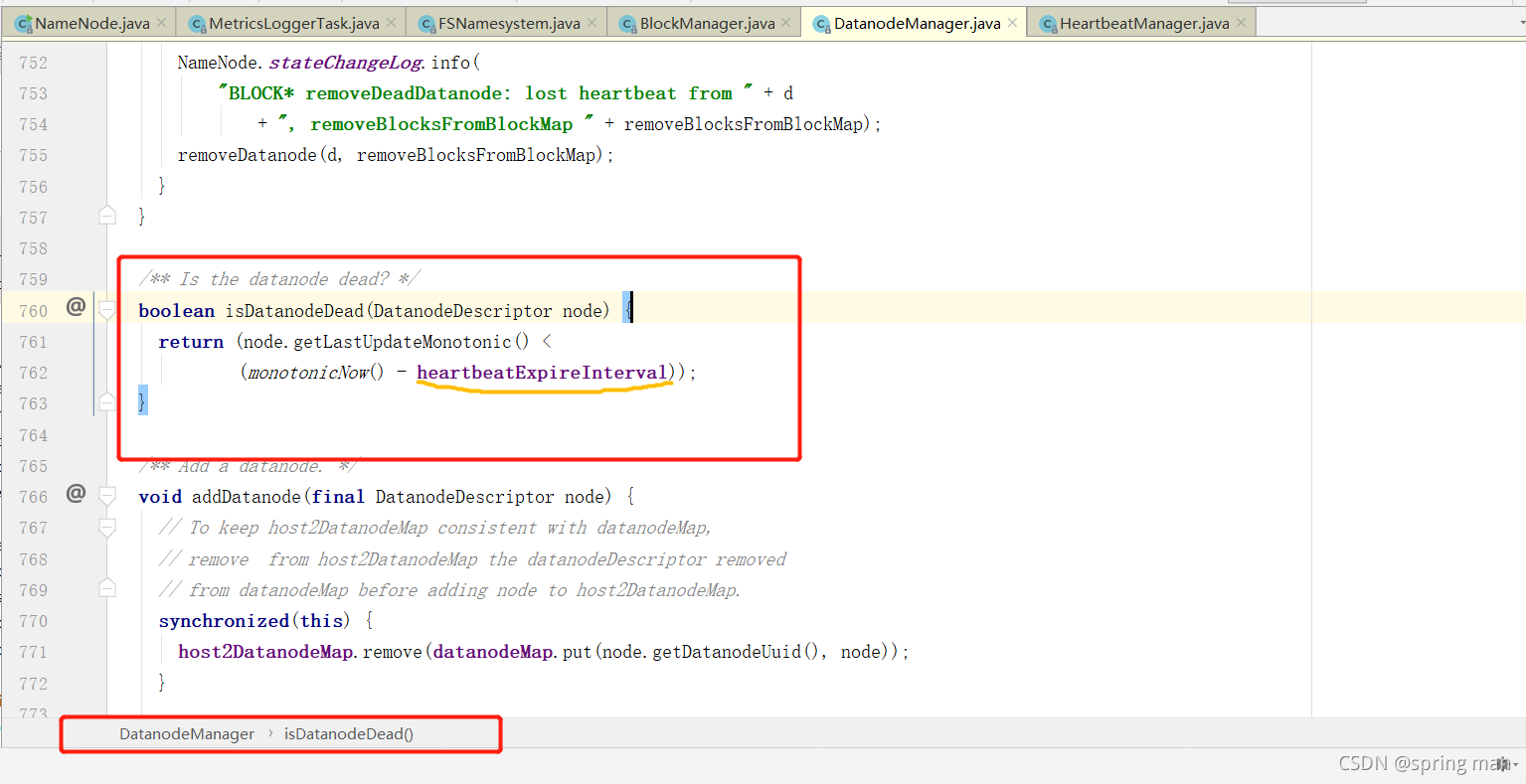
我们关注一个常量heartbeatExpireInterval。
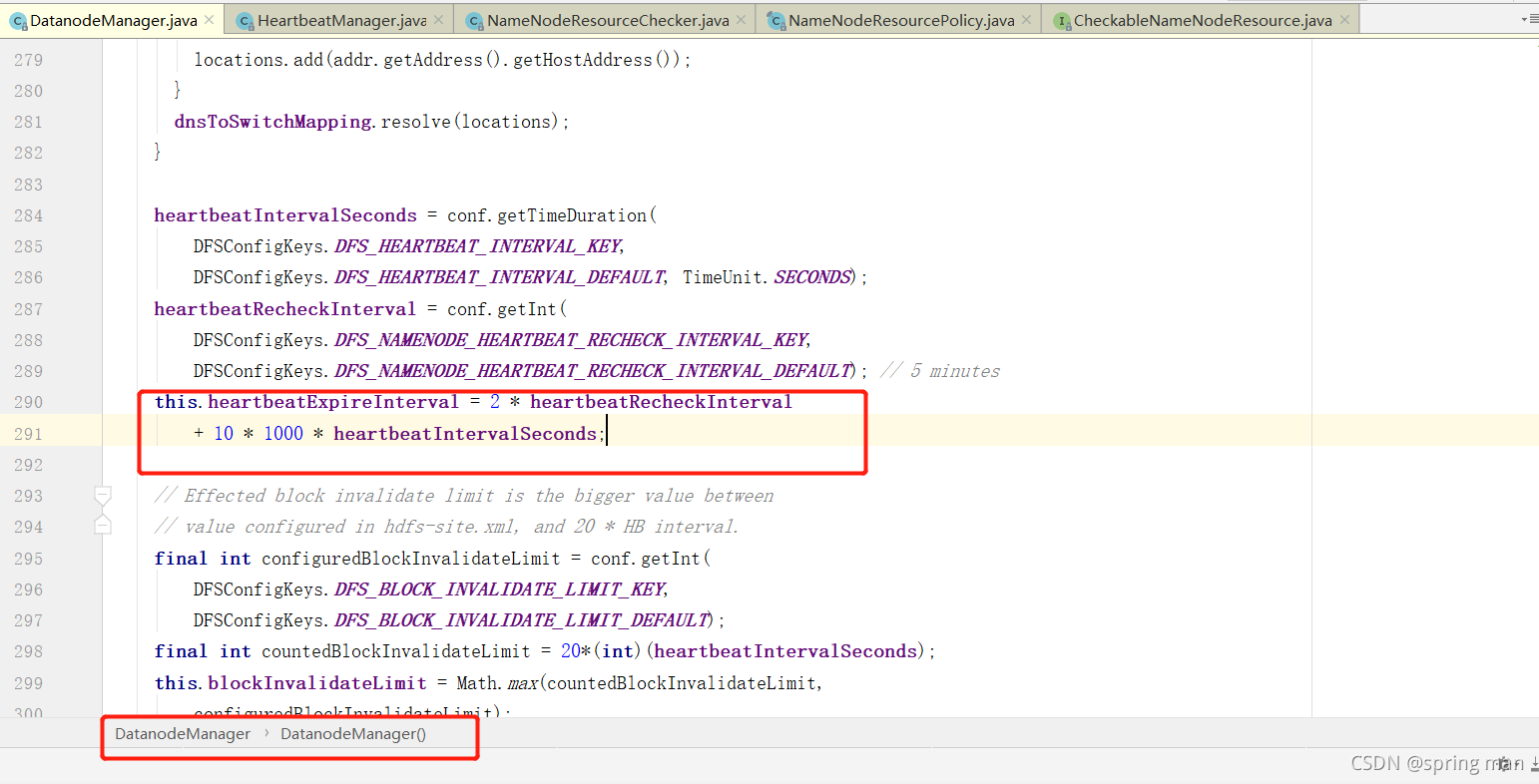
这个值就是10分加30秒。超过这个值,NN就认为DN死了。
检查是否进入安全模式
回到BlockManager的激活代码,进入安全模式的激活检查:

我们看它的阈值是如何界定的:
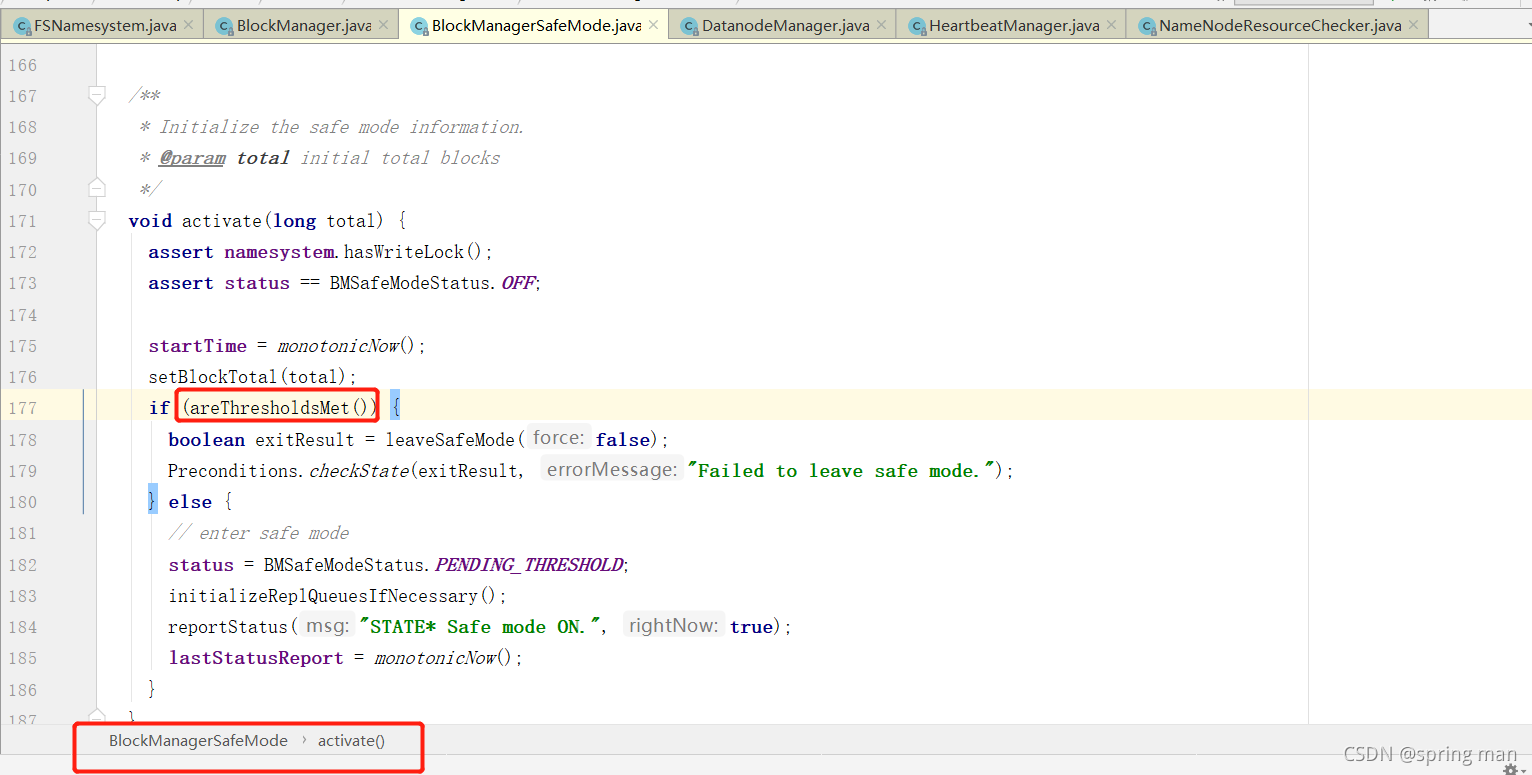
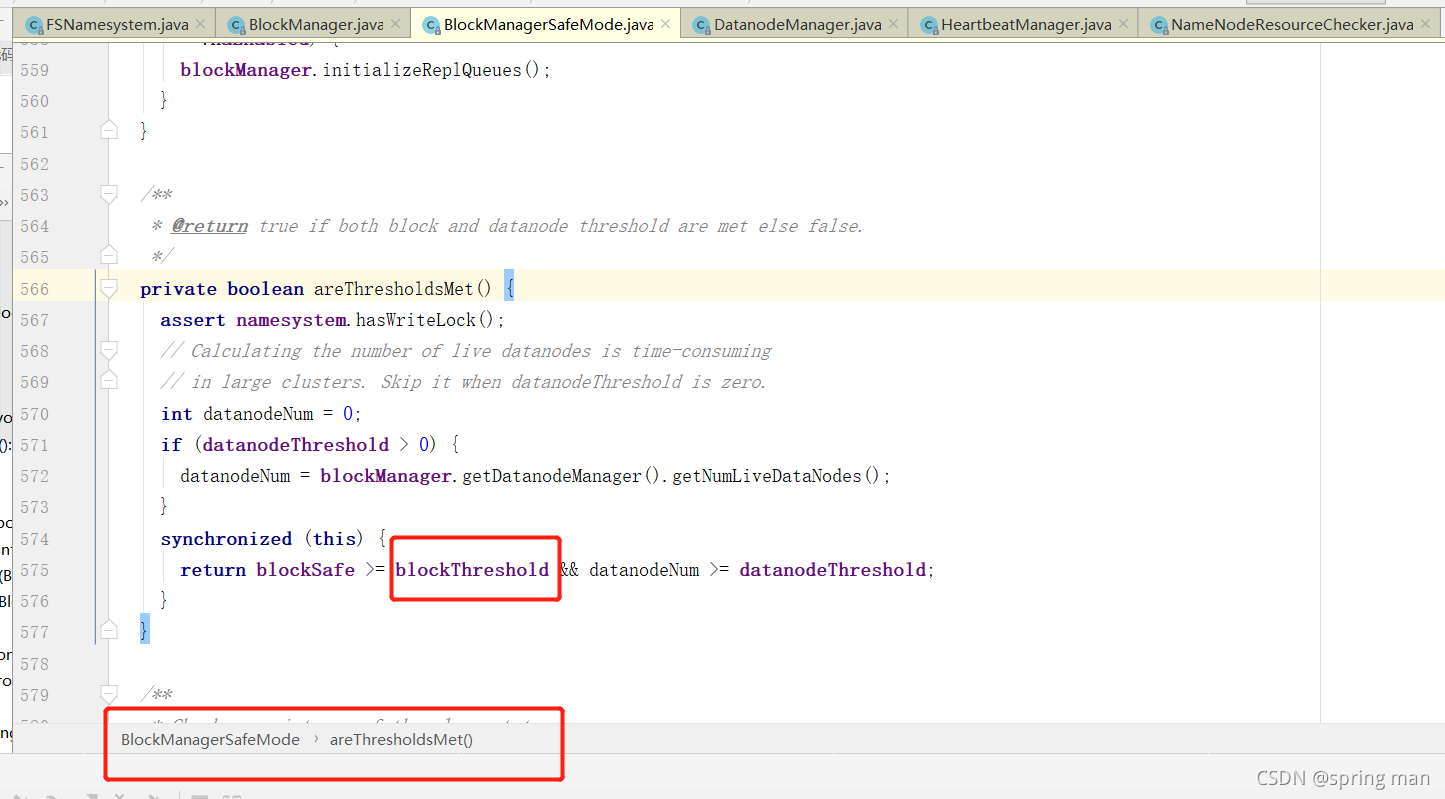
检查blockThreshold的值。
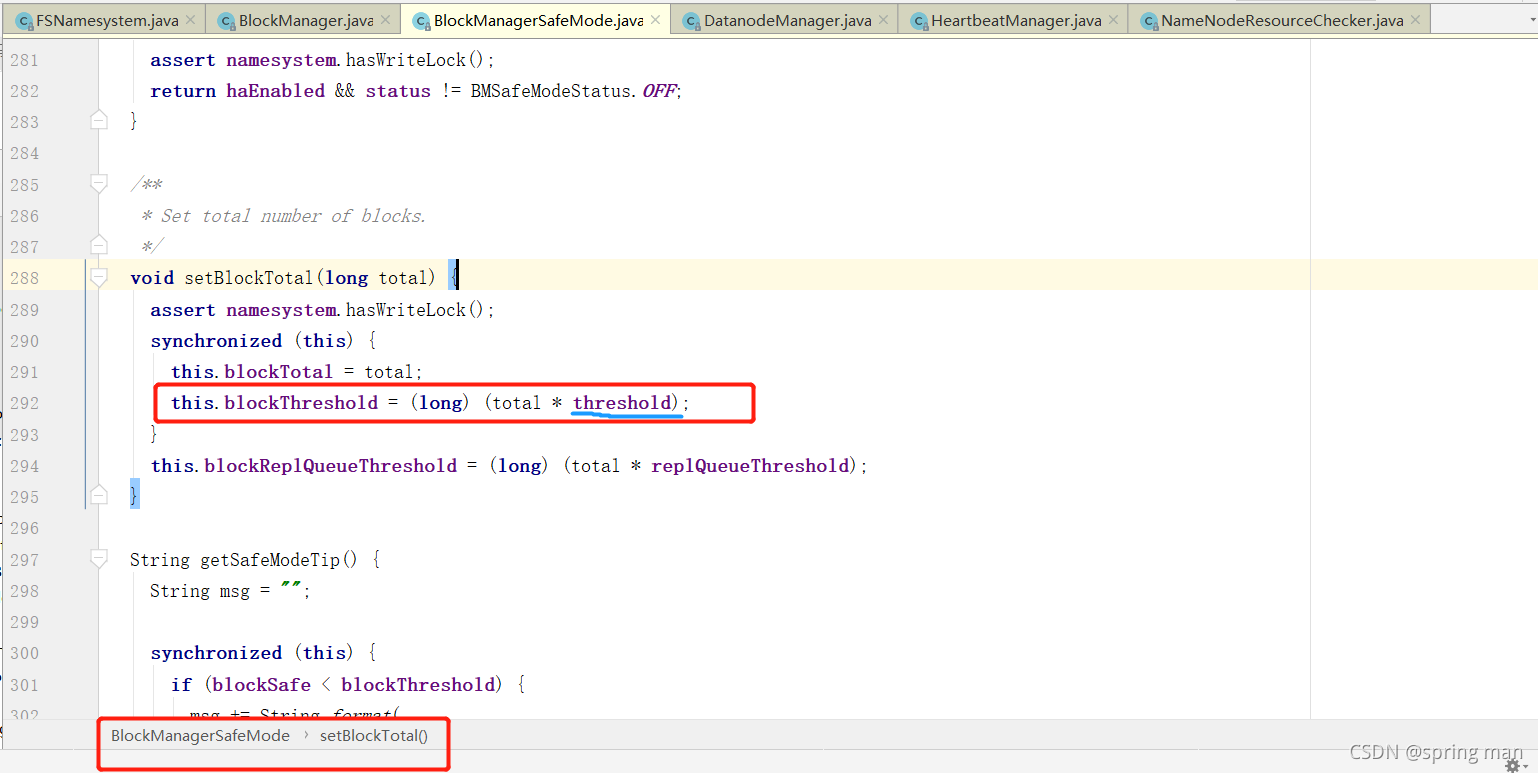
现在要去看看threshold的值。

它默认是0.999,也就是说,如果有1000个块,999个能正常启动还是可以启动的,如果有两个块不能启动那整个集群就不能启动。














 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









