







引起:
involution:
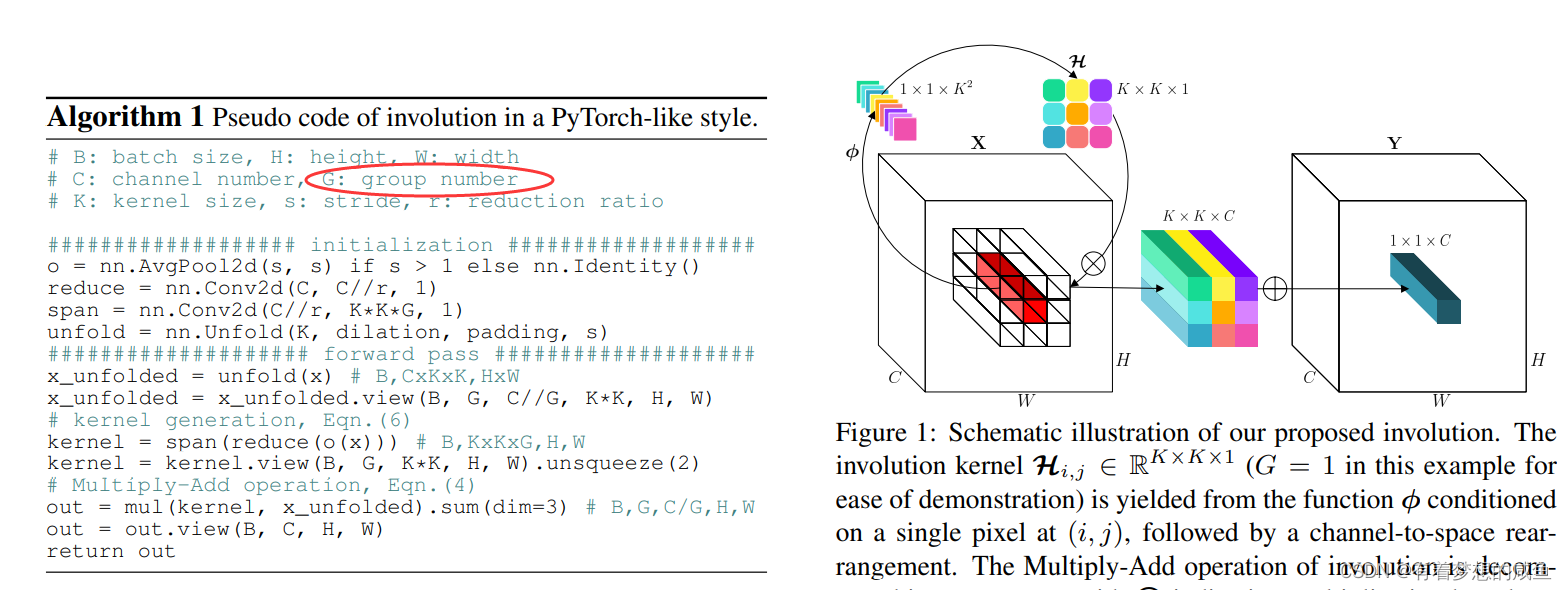
G-Group这是个啥?


我已经晕了,听师兄说这个H就是Group。。。不说了,先复习self-attention
self-attention:
Attention最核心的公式如下:
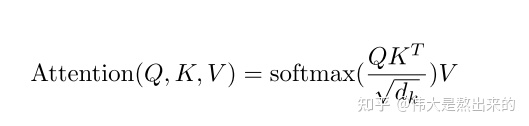
很难理解是吧,看下面的公式:
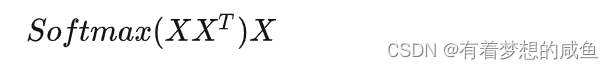
先抛开Q,K,V不谈,最初的公式是张这样的。
向量的内积代表啥,XXT又代表什么?
向量的内积代表的是两个向量的夹角,表征一个向量在另外一个向量上的投影。
XXT下面有一个实例:自己看吧
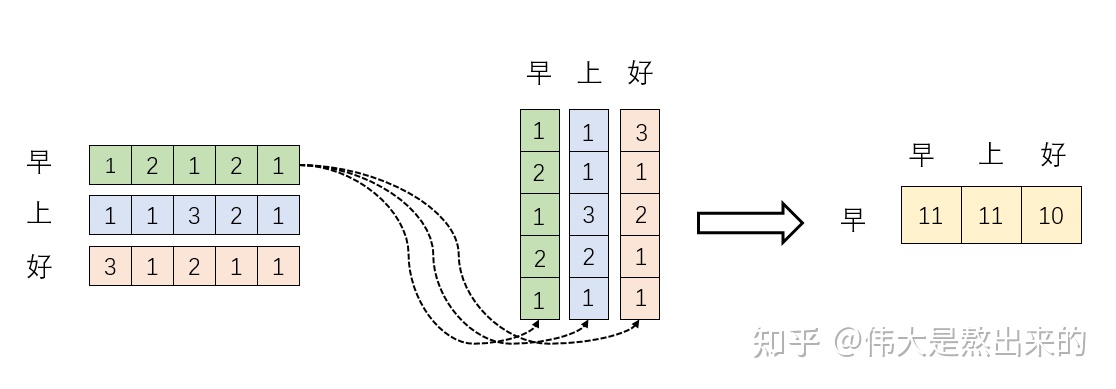
新向量的意义是什么?
是行向量 早 在自己和其他两个向量上的投影,那投影值的大小有什么意义呢?
投影值大,说明两个向量的相关度高。
更近一步,这个向量是词向量,词向量之间的相关度高代表什么?代表关注A词的时候,应该给B词更多的关注。
那softmax代表什么?

softmax有什么意义?
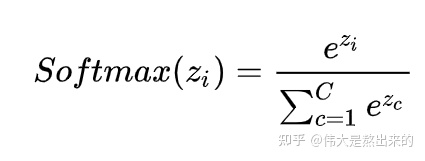
归一化
结合实例来看,softmax后数字和为1了。
那最后的X是什么意思?
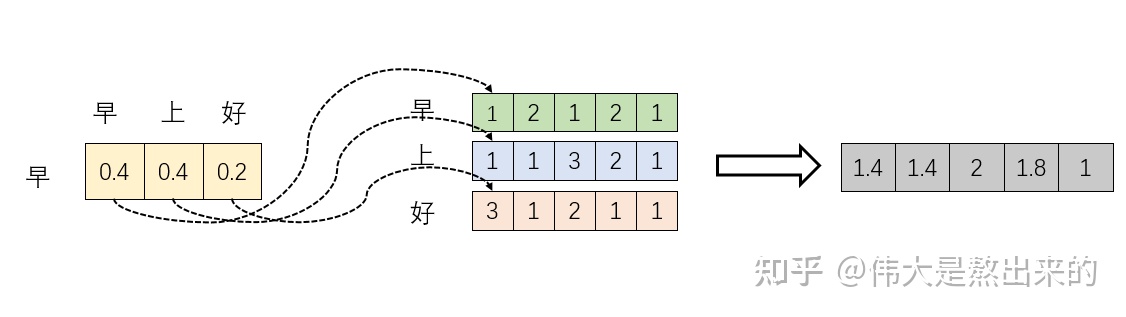
“早”向量的softmax向量与X的内积得到了一个新的“早”向量,这个新的行向量就是原来的“早”向量经过注意力机制加权求和后的表示
Q V K 矩阵:
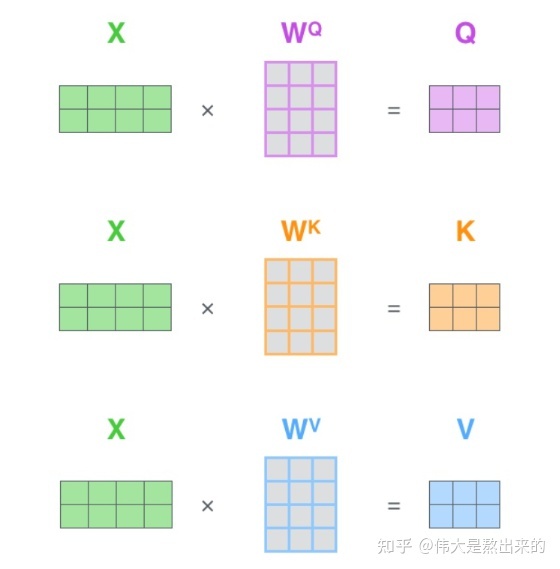
像QKV这样的,向量查询,信息查询,查询值,都是通过向量X经过线性变化得到的,本质都是X的线性变换。
为什么不直接使用X而要对其进行线性变换?
为了提高模型的拟合能力,矩阵W是可以训练的,起到一个缓冲作用。
不打字了,直接照搬了:

以上来自某乎大佬的博客:超详细图解Self-Attention - 知乎 (zhihu.com)
Multi-Head Attention:
老规矩,上公式:

Muti-Head怎么来的?
对于同一个文本,一个Attention获得一个表示空间,如果多个Attention,则可以获得多个不同的表示空间。
将h个head产生的Attention矩阵连接在一起后进行一次线性变换,使得输出的multi-head矩阵和输入矩阵的shape一样。 下面是结构图:

实例:
1:linear
对 Thinking Machines进行multi-head Attention计算。下图中矩阵X的第一行表示Thinking的词向量,第二行表示Machines的词向量, X dot W0Q/K/V 得到Q/K/V
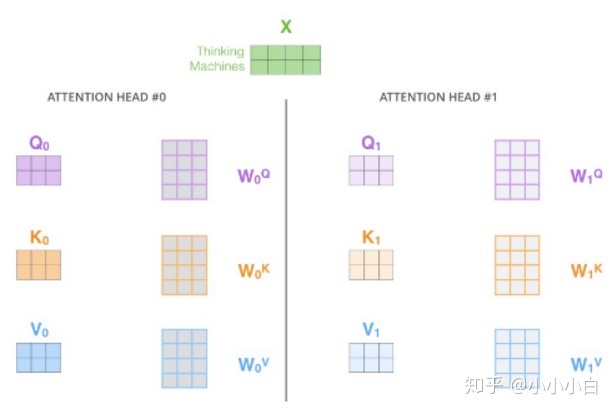
2:Scaled Dot-Product Attention
每一个head都要进行attention计算,由于有8头attention,会得到8个矩阵(2*3)。softmax对矩阵的每一行进行作用。
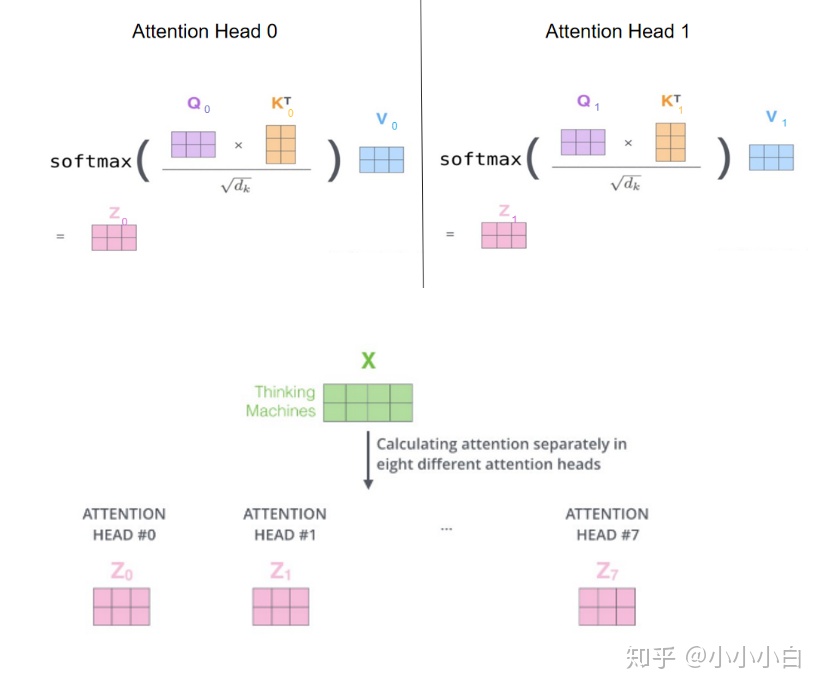
3:concat + linear
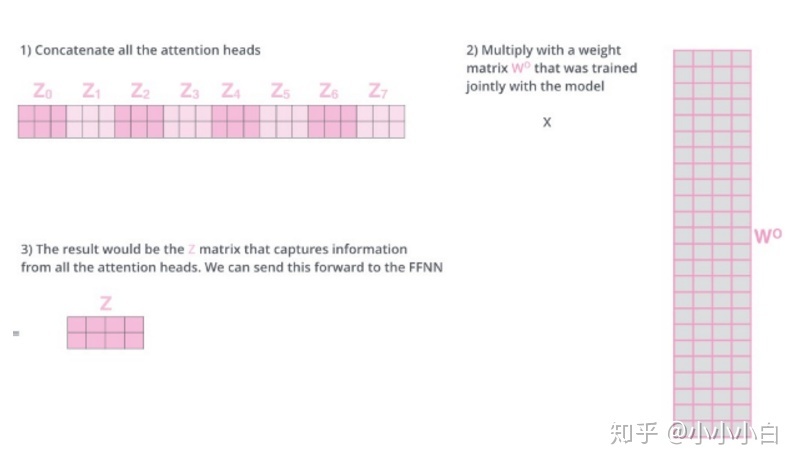
由于Multi-Head Attention后面可能紧跟前馈神经网络(或者RNN、CNN等),而这些网络接受的是单个矩阵向量,而不是8个矩阵。所以把8个矩阵连接在一起(维度2*(8*3)=2*24)然后再与一个矩阵(24*4)相乘,最后压缩成一个矩阵(维度2*4)。
4:最后一整个框图来表示计算过程:
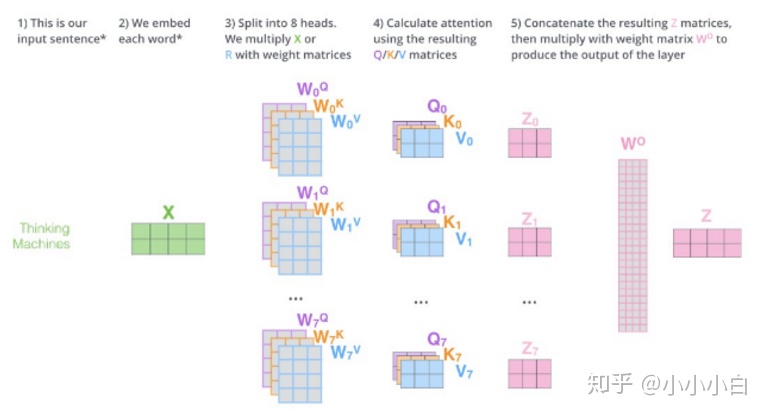
Multi-Head来自某乎大佬:















 3674
3674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









