读论文《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism 》

这篇文章跟《Efficient Large-Scale Language Model Training on GPU Clusters》都是有Nvidia做的大规模训练transformer的工作。这里主要介绍了tensor-parallel的方式训练transformer。
主要创新点在第3章:结合transformer的模型结构特点,介绍了如何做model-parallel,切分layer计算到GPU上,减小GPU之间的通信,增加并行度。这里利用了transformer模型的特点,切分的非常巧妙。
文章介绍的方式可以直接用pytorch实现,逻辑简单,不需要像GShard那样设计模型切分原语和编译器。而且这里是对tensor的切分,不涉及op计算逻辑的修改。所以后面还可以针对op计算做一些fuse操作,对parallel没有影响。对比mindspore是针对tensor维度切分,而oneflow是op维度的切分。同理,oneflow对op切分就造成op的实现需要感知parallel的存在。
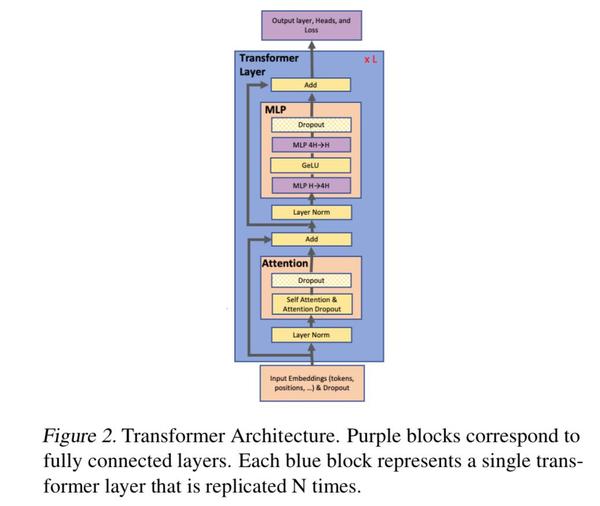
上面这张图介绍了transformer的基本结构,主要是multi-head Attention和两层fc的MLP (feedforward)
重点在下面这张图,介绍了如何切分GEMM,把layer切分到GPU上,并且减小GPU之间的通信。
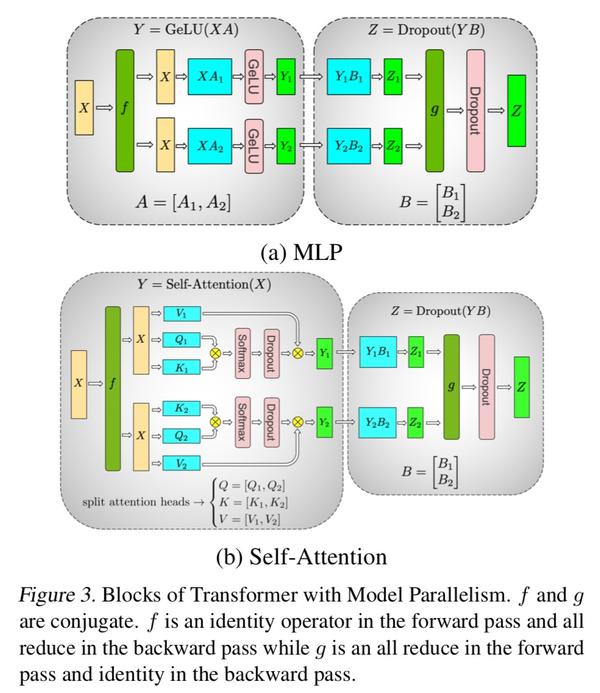
对于MLP层,把X做broadcast复制,把weight A按column切分,这样GeLU是element wise操作,可以不用再做all-reduce。然后直接接下一个FC,对第二个FC,只能做row切分,因为Y已经是column切分了。所以这里需要g做all-reduce。总体来看,这里只需要两次communication操作就可以了。
对于attention层,前面multi-head attention可以直接按head维度切,然后可以直接计算到attention完成,之后接FC,也是把weight 按column维度切,算完之后做all-reduce。总体也是只有两次communication。
上面这张图可以结合着另外一篇megatron的论文来看,其中在介绍model-parallel的时候,有这样一张图:


这里可以看到每个大框里面是一个transformer层,然后其中的4个小框就是transformer的attention和MLP,上图是按tensor-parallel为2来切的。在论文中是放到一个8卡的node上。
在megatron-LM这篇论文中,采用的是tensor-parallel+data-parallel,没有pipeline-parallel,在另外一篇中才介绍了跟pipeline-parallel结合在一起训练更大模型的问题。这里训练的模型最大只有8.3B。
这篇文章采用的V100,有24G显存。然后设置GPT-2的param为1.2B,单卡可以放下。再扩展就采用tensor-parallel的方式,最大扩展8-way,即占满单机8卡。tensor-parallel都是在单机内来做的。所以这里最大支持的模型只到8.3B,就是单机8卡支持的大小。之后采用data-parallel来实现scaling,最大scale到64机,总共512卡。
论文中测试了scale的效率,以单卡的计算力利用率作为baseline,计算扩展之后相当于能够达到baseline的多少。对于单机8卡可以达到单卡的77%,也就是8卡相当于实现了6卡的算力。然后512卡也能达到74%